

Types of requirements
Below are a few of the types of requirements that can be supported based on the configuration of the application and data layers.
-
Users from teams in disparate geographic markets should only be able to see and activate records that are from their geographies within the CDP (Customer Data Platform).
-
Users from a central global or corporate team should be able to see and activate all records in the CDP.
-
Global team members should be able to create campaign artifacts (templates) that the local market teams could use.
Key considerations / process questions
Regardless of the data isolation approach taken, the data model must be consistent across databases used by each region. This will allow for sharing of application objects across tenants.
There are two primary layers to take into account when defining a solution to support the required data isolation, the data layer (databases), and the application layer (Redpoint Interaction).
The application layer supports a few different features to enable data isolation. The foundation layer of RPI (Redpoint Interaction) is the RPI cluster. Clusters support one or more tenants, and within a tenant you can configure organizational nodes to isolate the application objects and data access controls more granularly.
The data layer needs to be configured in coordination with the application layer deployment in order to achieve the appropriate level of data isolation and access control at the application layer.
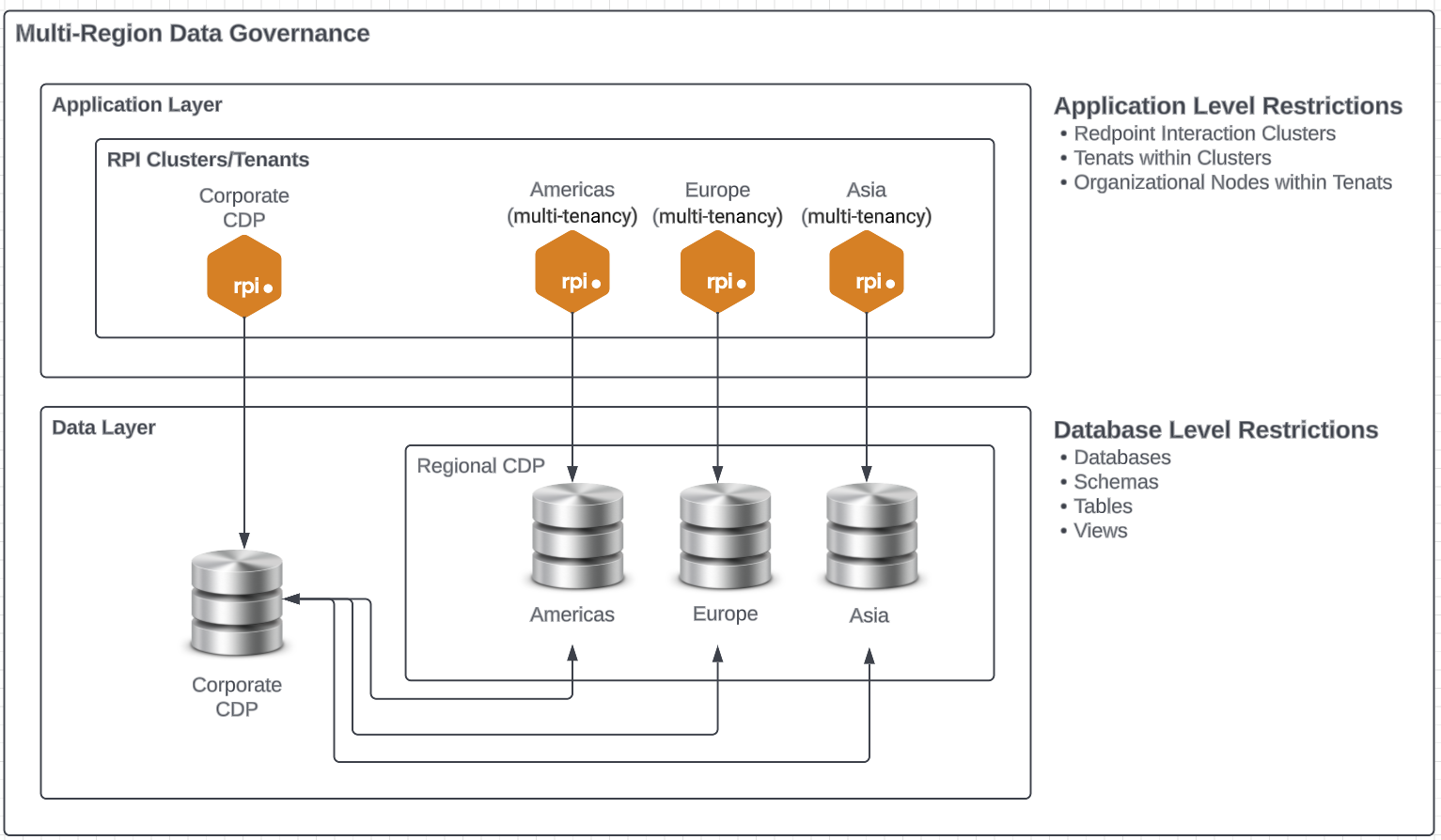
High-level visualization of deployment components
This diagram is intended to help you visualize the components that support the various deployment options at a high level. In the following sections, we provide additional detail on the deployment options as well as various questions and considerations when determining what deployment is most appropriate for the clients' requirements.
Considerations and questions
-
What level of control does global need to exert over the various business units?
-
Who will have access to source data for the various units?
-
Direct database access vs application-level access
-
-
Will the majority of engagement activities be initiated from global or regional units?
-
How will the databases be distributed globally and across regions?
There may be requirements to isolate data to specific regions for multiple reasons, as well as an international CDP to match data across the organization. The requirements may necessitate the data layer be distributed in one or both of the following ways.-
Master CDP: All regions/countries
-
Regional CDP: All countries in a specific region
-
Both Master and Regional CDPs
-
-
What does global access need?
-
Access to all campaign executions from a single instance?
-
What level of campaign data latency can be tolerated (none, once an hour, once a day, once a week)?
-
-
What are the global requirements for reporting?
-
Data access (corporation wide, region, country)?
-
Latency: if corporate-wide or regional, can latency be tolerated?
-
-
Should global campaign assets be managed from a single instance or per region/tenant?
-
Selection rules
-
Audiences
-
Assets
-
Campaigns (interactions)
-
-
Does the client need to be able to send both corporate Interactions and regional Interactions from the same tenant?
-
If using single customer view, should users be able to see the data at the corporate level as well as the regional levels?
-
Various high-level deployment options
Below are examples of various deployment options and some details related to the various options.

Details related to deployment options
-
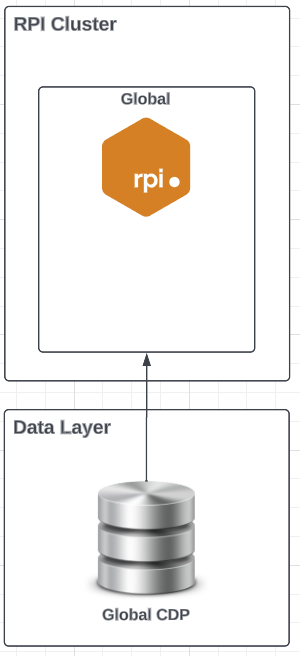
One Cluster, One Tenant, Zero Organizational Nodes
This is the simplest deployment model with minimal configuration.-
All data available via one RPI instance and available to all users.
-
Single customer view and reporting available in one database.
-
Global data access for all users.
-
-
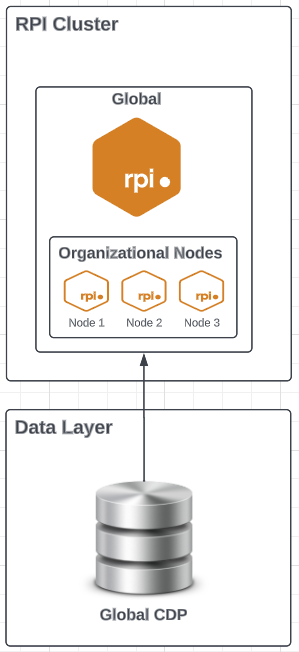
One Cluster, One Tenant, Multiple Organizational Nodes
Use organizational nodes to support a level of user access and data segregation at the application layer. Requires data layer structures to support this configuration.-
All data available via one RPI instance but isolated based on the defined organizational nodes.
-
Requires data to be isolated in separate tables or views based on restricted access requirements.
-
Restricted data access based on assignment of organizational nodes. Supports assigning individuals to a single or multiple organizational nodes or the top organizational node, which will provide global access to all other nodes.
-
Single customer view and reporting data available in one database.
-
-
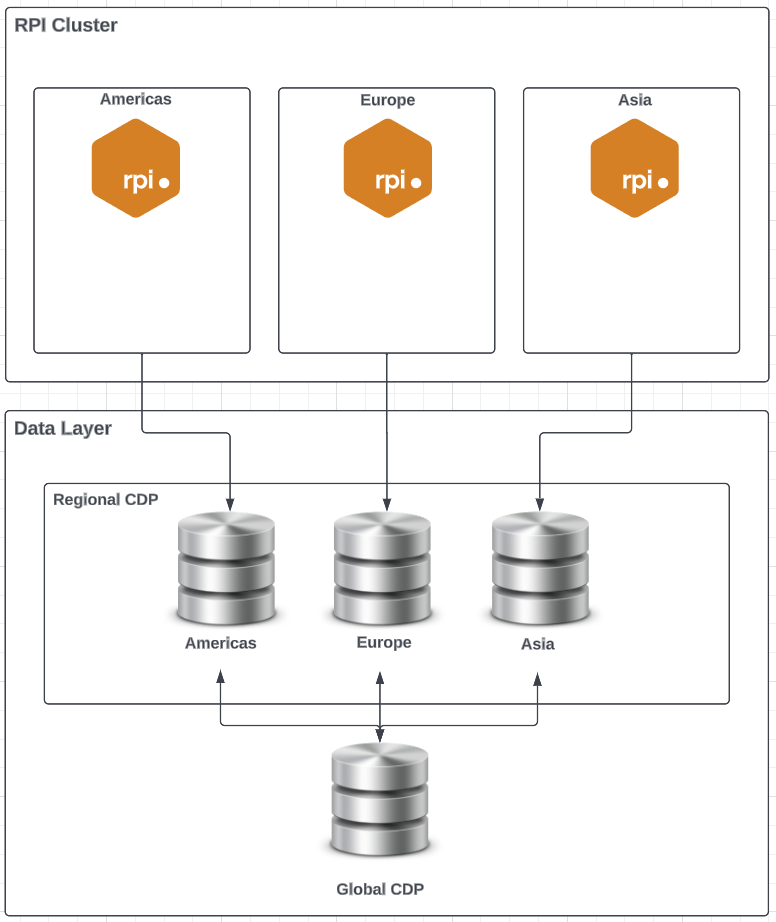
One Cluster, Multiple Tenants, Zero Organizational Nodes
Use of tenants as organizational nodes to support data segregation. A server in one region/country supporting multiple tenants to support data isolation/access per country. In order for this to work, you will need to have multiple databases, schemas, or views that isolate a set of data for a given country.-
Data isolated per tenant, requiring the need to login to a seperate tenant for the appropriate access to the data based on the level of data segregation.
-
Requires that the data layer is configured to support this via seperate databases, schemas, tables or views. The configuration of the data layer would be based on the amount of segregation required at the data layer.
-
Campaign history will be isolated to each of the databases/schemas that are defined for each of the tenants.
-
Global campaign access will require logging in to each individual tenant.
-
Single customer view and reporting data will be accessible within each tenant.
-
Global data access will not be accessible via a single database and will require consolidation to a global/central database to get insight into the campaign activity across tenants.
-
-
One Cluster, Multiple Tenants, Multiple Nodes
This configuration is similar to the previous one but would allow for segregation per region by tenant and then organizational nodes could be used to isolate the data for each country within the region.-
This would allow for global access per region but not across regions.
-
Consolidation would need to be done to see all the data across all the regions/countries.
-
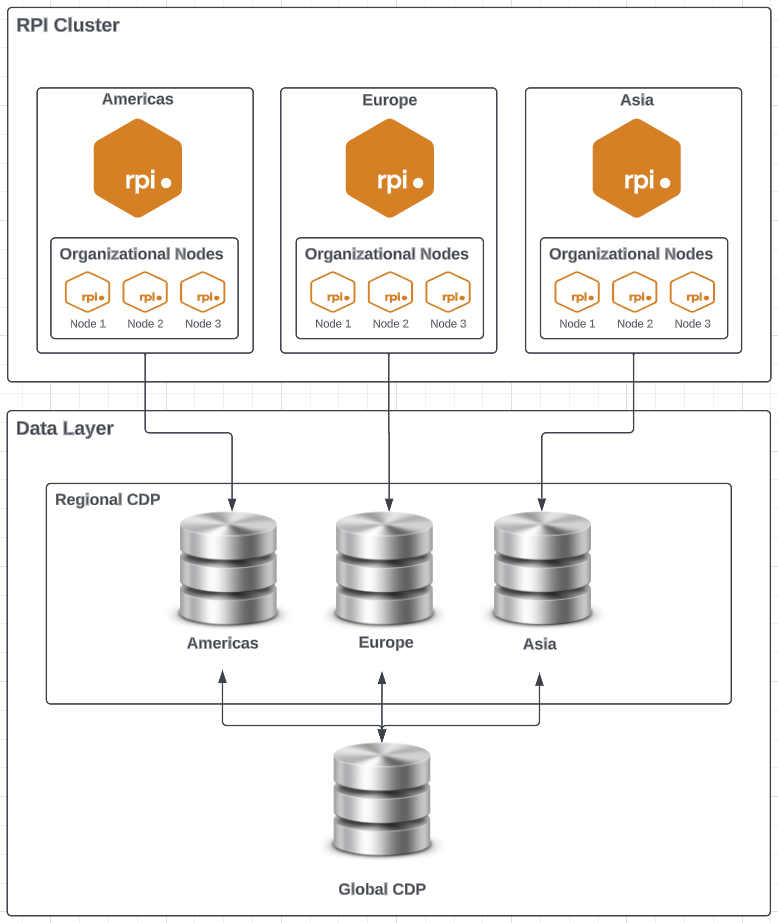
-
Multiple Clusters, One Tenant per Cluster, Multiple Nodes for Regional Clusters and no Nodes for Global Cluster
This configuration supports a sophisticated deployment that allows for regional cluster deployments with nodes for countries and a global cluster for corporate communications. This provides the greatest level of data segregation along with global and regional communication functionality.
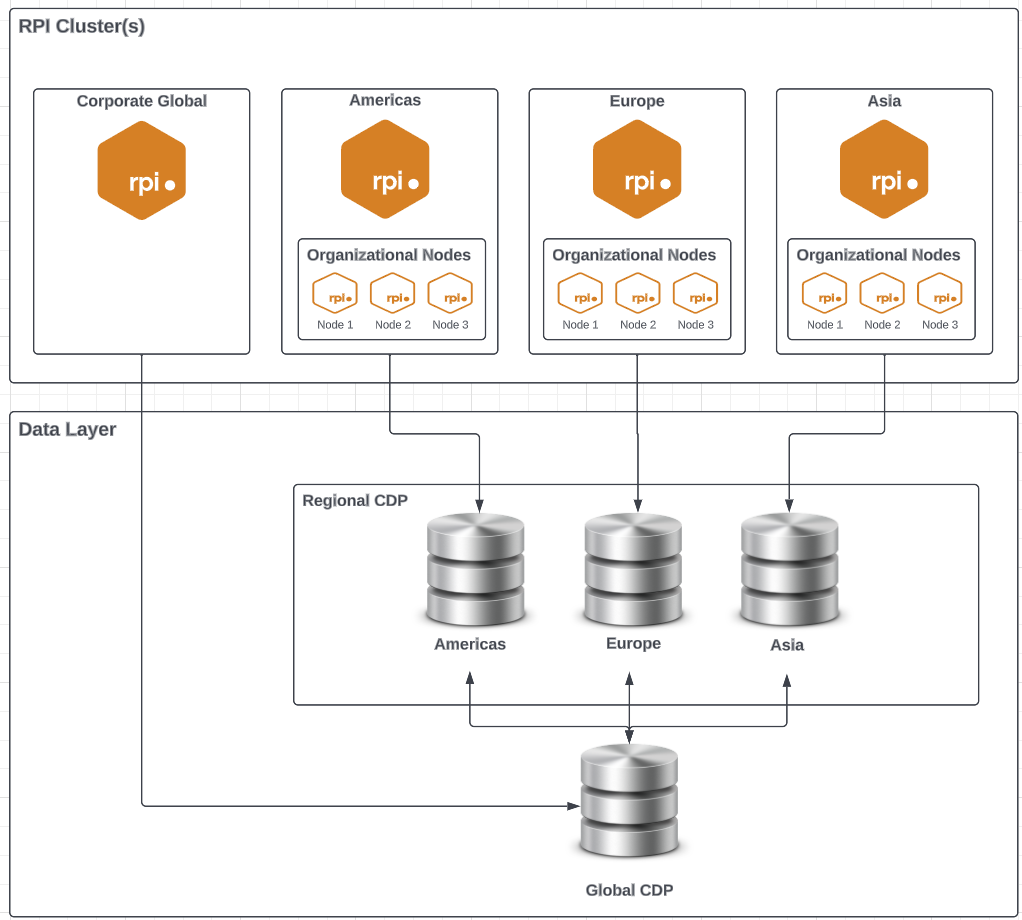
Considerations when determining deployment model
-
One tenant with nodes will allow for global node to see all the objects in the tenant.
-
Separate tenants will require that a global user logs into each tenant.
-
If a global tenant is created along with regional tenants, then the data will need to be synced to the primary data warehouse for cross-campaign reporting and global campaign execution.
-
In order to support multiple clusters or tenants and perform central reporting, you may need to seed some of the offer history IDs to simplify consolidation of the data to a central repository.
RPI organization capability (application layer)
In addition to the data layer, organizations and linked nodes in RPI can be used to keep regions' and countries' operations separate. Below are some details on creating and applying the organization feature in RPI. In addition to these items, you need to set the System Configuration setting EnableOrgNodeConfigUserControl to true for the permissions to be applied to the users within the system.
-
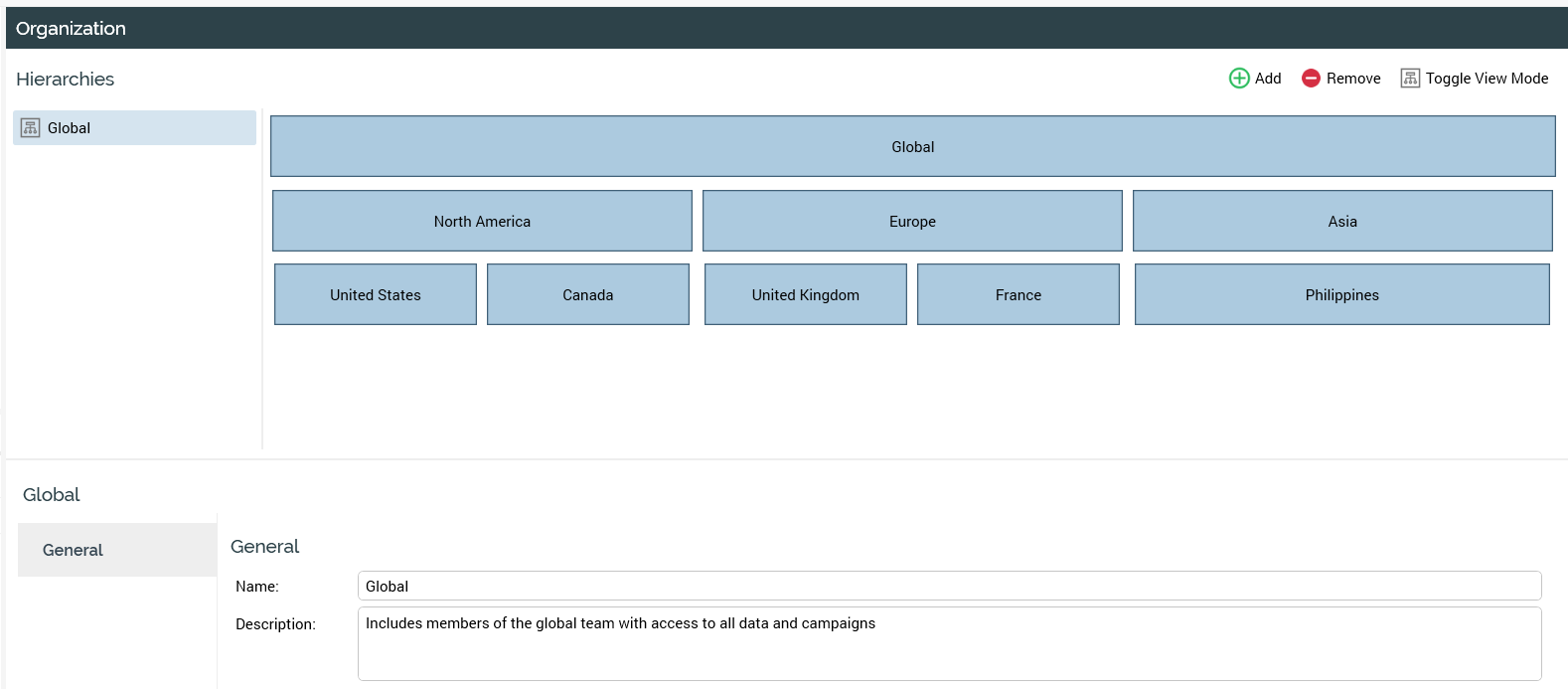
Organizations are the Redpoint CDP’s RPI functionality enabling the configuration of a hierarchical organization structure within RPI. Organizations are made up of nodes that represent units within the organization. The hierarchical nature of the organization entity can be set up to provide wider data access at the top levels of the tree.
-
In the example above, the organization contains three levels, with the highest level representing the global level, and the lower level representing countries. When defining the organization within RPI, the number of levels is configured based on each client’s needs.
-
Individual users are associated with nodes within this organization structure, enabling control over access to data and audience selection by linking resolutions and audience definitions to organization nodes. This allows users within an organization to be limited to the data associated with the specific organizational nodes to which they are assigned.
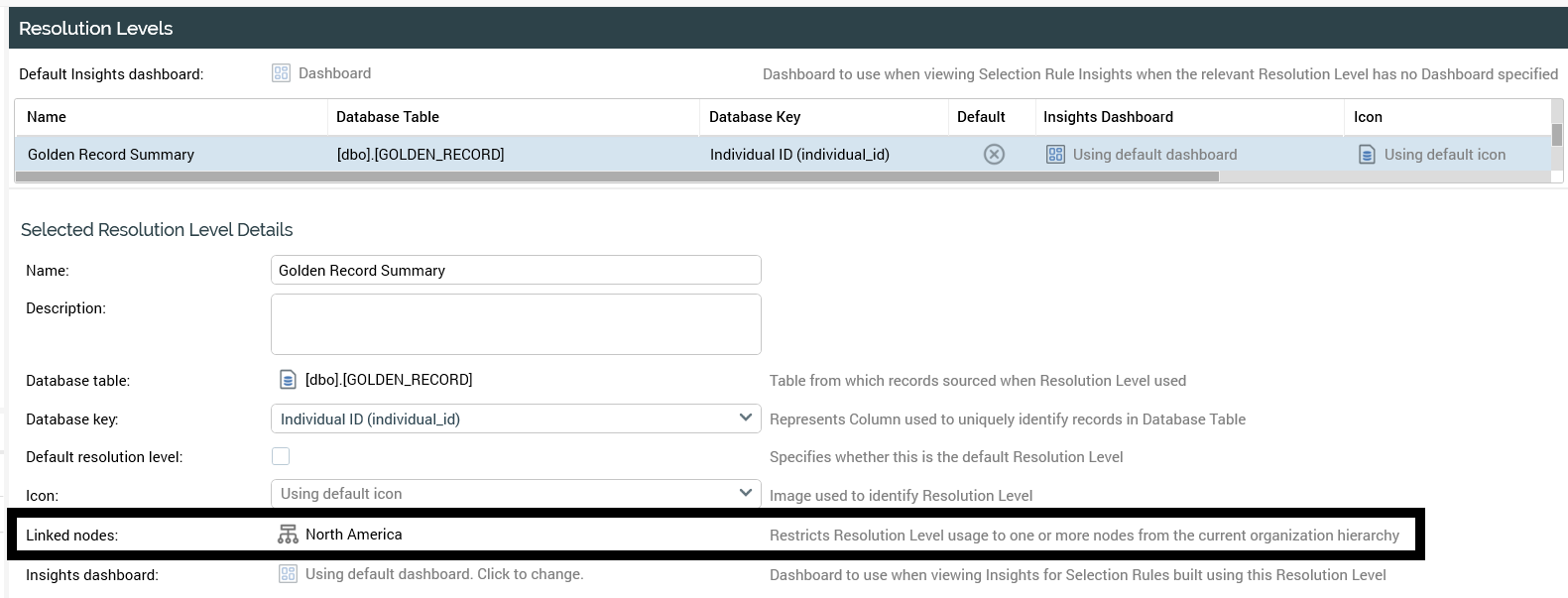
Resolutions: linked nodes
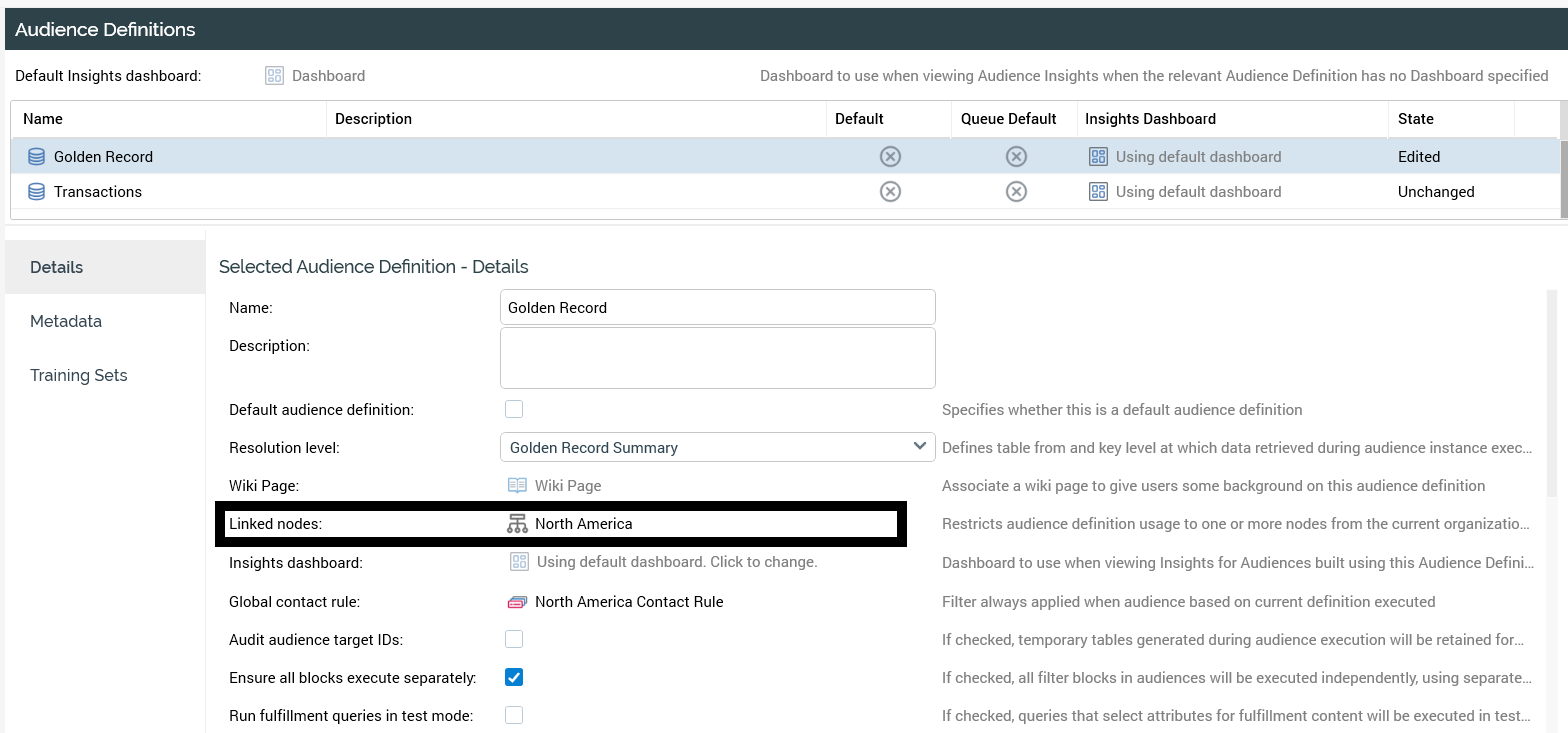
Audience definitions: linked nodes
-
Interactions can be assigned to linked nodes as well, but the audiences and selection rules that are used in the audience need to be managed by creating a file system that has folders for each of the nodes so that the objects can be managed by the file system access.
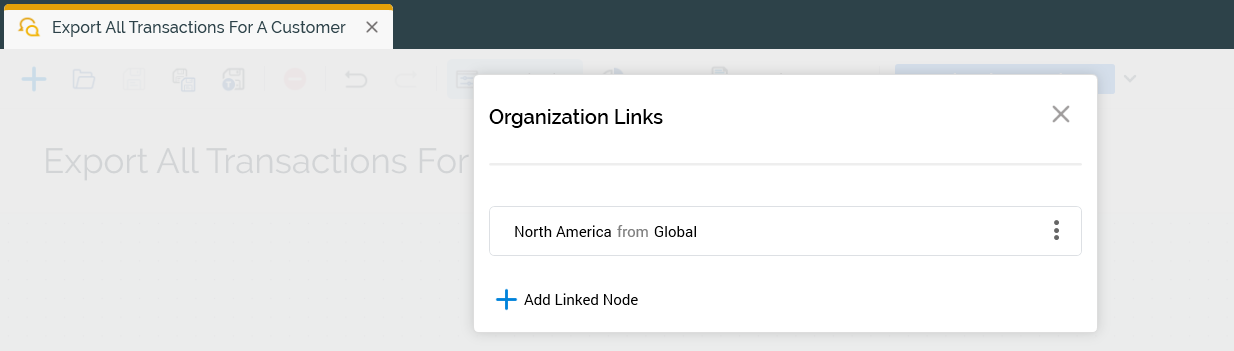
Interactions - Organization Links
-
Managing and sharing campaign objects
Each of the various deployment models support different options for configuring the environments as well as allowing for objects to be managed and shared across each of the application deployments. Below are some details related to various components.
Folder structure
When organizational nodes are used as a part of the deployment model, a folder structure and supporting permissions need to be applied to implement the deployment. Attributes, selection rules, and audiences do not have a way to assign an organizational node to them, so you need to assign the permissions to the folders that these objects are stored in. Creating a folder for each of the organizational nodes and assigning the appropriate permissions is required to support applying this feature to file system objects that don’t have a linked node setting within the particular asset designer.
Selection rules, audience, and campaign (interactions) templates
Campaigns within RPI are built from a hierarchy of objects including selection rules, audiences, and interactions. Each of these components can be built independently for a given tenant or organizational node or they can be managed globally and deployed for use by other tenants and organizational nodes. A combination of both global and independent object creation could also be a viable approach.
When considering use of globally defined objects, how those objects are disseminated to the lower environments depends on the deployment models.
-
Deployment to organizational nodes within a tenant the objects can be copied to the appropriate node.
-
Deployment to other tenants within a cluster can be done by copying the objects to the other tenants.
-
Deployment from one cluster to another cluster will require exporting and importing of objects or the use of the integration API.
Some deployments will require some or all of these options to support the appropriate distribution of objects throughout the global environment.
Single customer views
Single customer views are available within a given tenant, but they do not work natively across tenants. If you want to have a global view of the data, you will need to propagate the data to a global database/tenant to support that type of view. In that case, it is recommended that only the data that is required for the view be propagated to minimize the amount of data and the timeliness of the data propagation itself.
Offer history
There are various considerations when it comes to offer history relative to data isolation and when more than one cluster, tenant, or organizational node is being used, primarily as it relates to the IDs that are used by the offer history tables. If the offer history tables are to be kept in complete isolation, then the IDs can be left as is (default), but if there is any consideration to get a global or regional view of the data, then the IDs that are used by offer history should be seeded so that there is no overlap in the IDs, so that when the data is combined there is no collision of data that would cause duplication or prevent the identity of what system the data originated from.