

Overview
Redpoint CDP supports both a complete Redpoint-managed SaaS solution as well as a data-in-place architecture for you when utilizing Snowflake or BigQuery. The data-in-place approach allows you to leverage your own database environment where all data is persisted within your security perimeter. Details on these two options are explained in this document.
Redpoint CDP full SaaS
In a Redpoint CDP SaaS deployment, the application stack and database are hosted and managed by Redpoint. This provides you with a turnkey SaaS solution ready to ingest data and begin executing audience segmentation and engagement activities. The Redpoint CDP SaaS solution includes the Redpoint CDP data model, providing a core into which your data is loaded and enabling standard identity resolution and golden record creation functionality.
Redpoint CDP data-in-place
With a data-in-place deployment, your data is persisted only within your data environment (Snowflake or BigQuery). The data is queried for constructing customer profiles and executing audience creation, but the customer database is all managed within your environment. In this scenario, Redpoint hosts the application stack and databases related to application operations only; the customer data store remains within your environment. Redpoint CDP outputs including segmentation history and golden records are written directly into your database.
Differences between full SaaS and data-in-place
The primary difference between full SaaS and data-in-place options is:
-
Full SaaS deployment: the database that hosts the data for the CDP is managed by Redpoint. Redpoint will host the applications and the database, and the complete environment will be within Redpoint’s control.
-
Data-in-place deployment: the database is hosted in your cloud environment. The ability to host the database in a cloud project managed by your organization allows for the data to stay within your environment and be managed by your data security policies. Data may flow into the Redpoint environment for processing or data activation, but it will be persisted only within your data environment.
This illustration shows the databases in the green box, at the bottom right, indicating that they can be either in Redpoint’s or in your cloud environment.
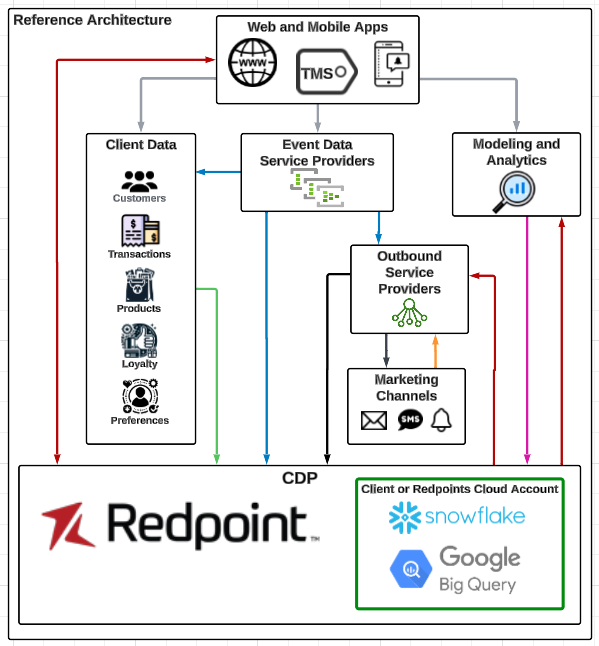
Data model deployment
Whether managed within Redpoint’s or in your data environment, you may choose to deploy the Redpoint CDP data model.
-
When deploying with the Redpoint full SaaS model, you are deploying with the standard data model template along with Redpoint’s Data Observability and Ingestion process to bring the data into the standard data model. This allows for Data Activation and other features to be preconfigured and enabled and minimizes your time to go live with campaigns.
-
If you are managing the database, then you have a couple of options:
-
One is to use your data model as-is and configure the data activation tool to fit your existing data model. This will take more time and require a custom configuration of the Data Activation tool and may require additional tables or views to be created to support the results you are looking to achieve with the platform.
-
Alternatively, you could take your existing data and leverage Redpoint’s standard data model within your data environment. This would allow for Data Activation to be preconfigured as it is in the full SaaS option and will minimize the time to value of the solution.
-
Either approach is viable and has its own benefits, so it will come down to what is best for your particular business needs.
Technical architecture
For a data-in-place deployment, Redpoint hosts and maintains the application stack, and you maintain your database. This type of deployment requires that you provide Redpoint with appropriate credentials and network access to connect to your database. Redpoint will read from and write to your database based on the use cases you implement within the Redpoint software.
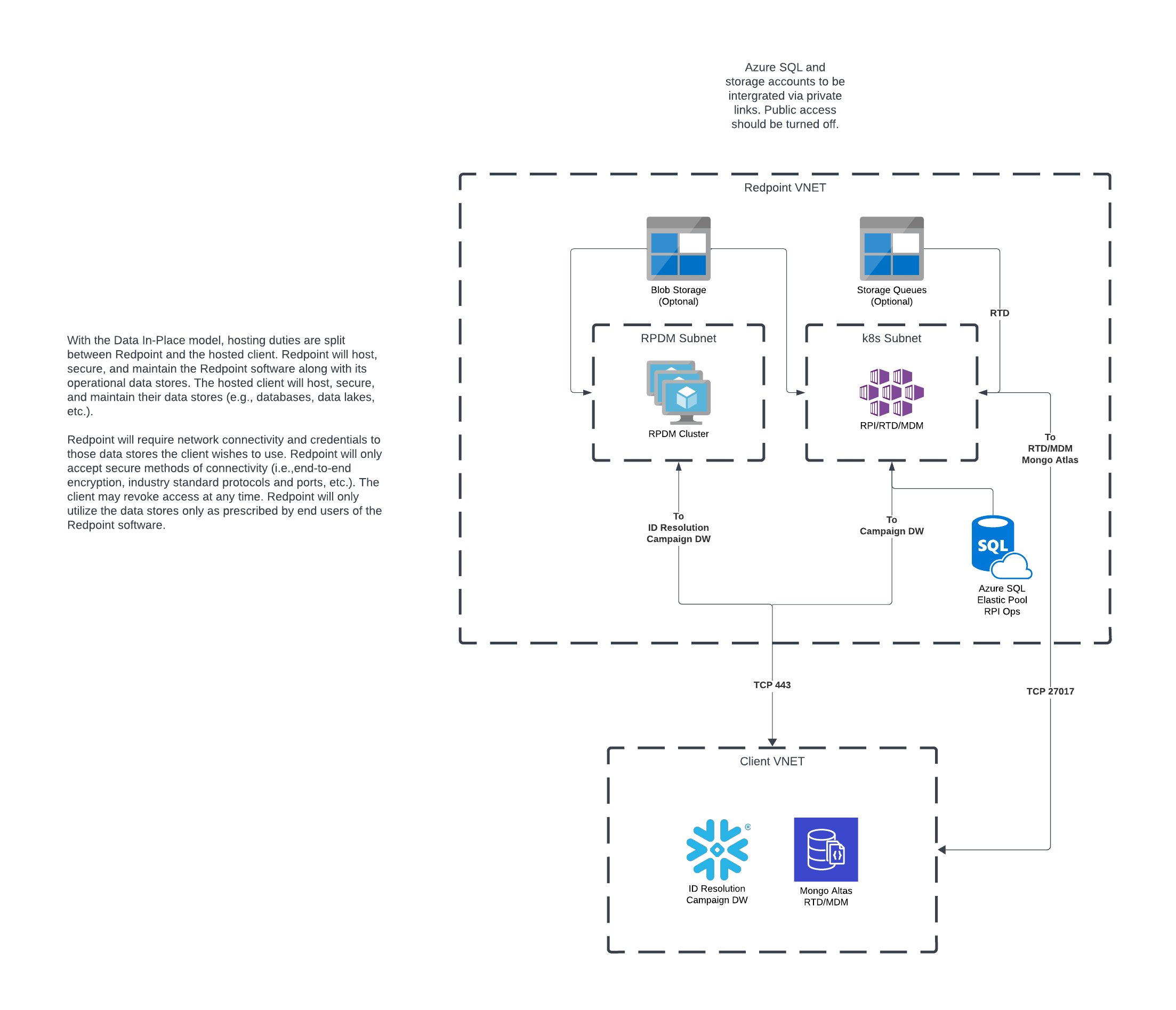
Data flows for data-in-place use cases
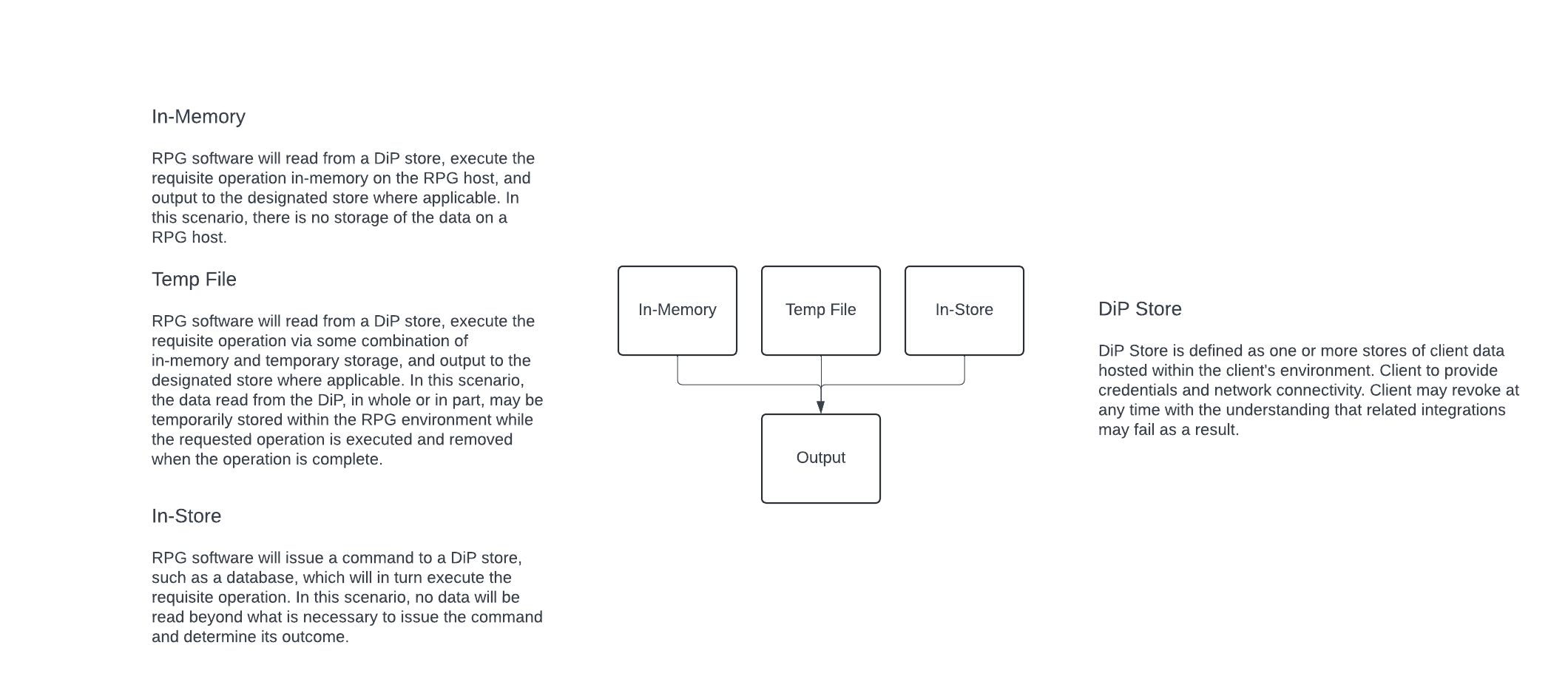
In a data-in-place deployment, data flows between the data warehouse and Redpoint applications during use case execution, however the data does not persist on Redpoint servers. There are three common operations for data-in-place processing:
-
In-memory
-
Temporary file
-
In-store
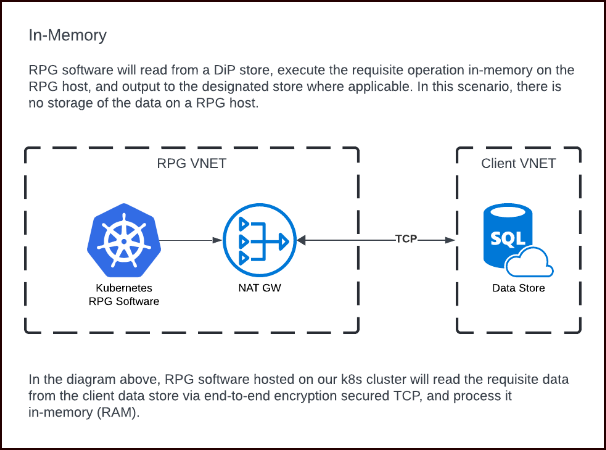
In-memory
For in-memory processing operations, Redpoint software will query the data-in-place store, execute the necessary operations in-memory on the Redpoint application hosts, and output the result to the designated location. For this type of operation, no data is stored on a Redpoint host server. Common examples of this type of processing are audience counts and single customer view requests.
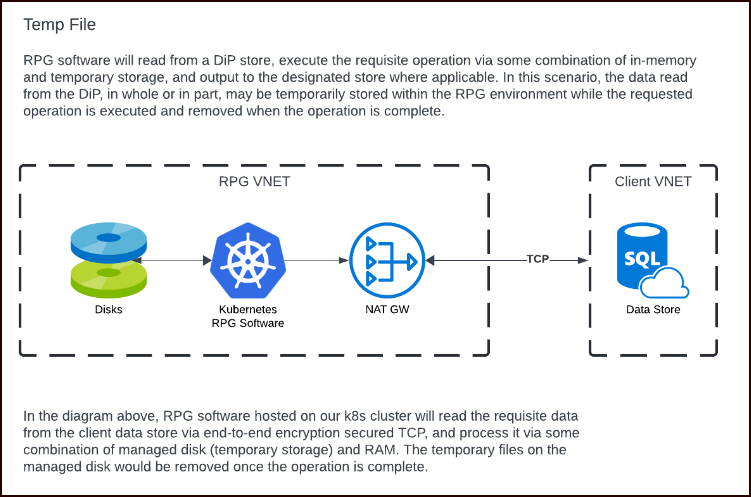
Temp file
For operations requiring a temporary file, data is read from the data-in-place store, written to a temporary storage location within the Redpoint environment, and removed once the processing is completed. Common examples of this type of processing are data integration, audience exports, or larger-than-memory operations.
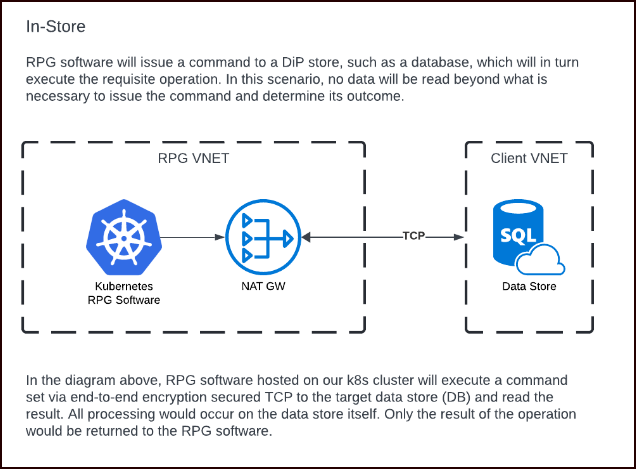
In-store
In-store processing occurs when the Redpoint software issues queries against the data-in-place store that result in operations occurring only within the data store. Common examples of this type of processing are audience segmentation activities.
Additional considerations
-
Do you have an existing database that is fit for purpose and want to sit data activation on top of it, or will you need to build a new database while deploying the Redpoint data activation software?
-
Do you want to manage the database in a cloud provider or have Redpoint do that on your behalf?
-
Do you have any compliance or consent restrictions that require you to manage the database?
Frequently asked questions
How is database usage charged?
For data-in-place deployments, the database usage (including storage and compute costs) is billed by the database provider to their customer.
Does data ever leave the data cloud?
Yes, data leaves the data cloud as specified in the data flow diagrams above. Specifically, data is queried by the Redpoint application in order to fulfill customer use cases, including data integration, data quality, selection, analysis, and activation of audiences. It is queried and processed but not persisted within the Redpoint environment.