

A chokepoint is a processing step that causes all of the data to be read before a single record can proceed. Mostly commonly it involves a sort—either explicitly using a Sort tool, or implicitly using the Join, Summarize, Unique, or Rank tools.
The problem with a chokepoint is that all processing before the chokepoint must complete before anything after the chokepoint can proceed. Sometimes this is necessary due to the nature of the processing, but sometimes it can be avoided.
The first thing to consider is whether the data needs to be sorted at all. Avoiding split-merge bottlenecks explains how to keep already-sorted records in order through the processing steps. By using these techniques you may find that your data is already in the order you want.
Also realize that tools causing a sort of the record streams necessarily leave the data sorted as a side effect. For example, the L, R, and J outputs of a Join are always sorted in ascending order by the specified join keys. Similarly, the Unique, Rank, and Summarize tools leave their outputs sorted ascending by the specified keys or group fields.
A similar case occurs when you join one table against another and then perform some processing (for example, supplying default values), on the L or R "outer" output of Join.
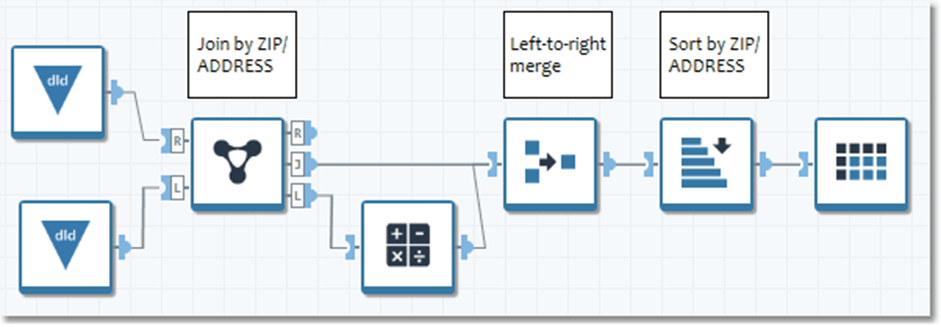
The Left-to-right merge type used to combine the record streams causes the records to be out of order, requiring an additional sort. It also causes the records from the J output to spool to disk waiting for all of the L records to be read.
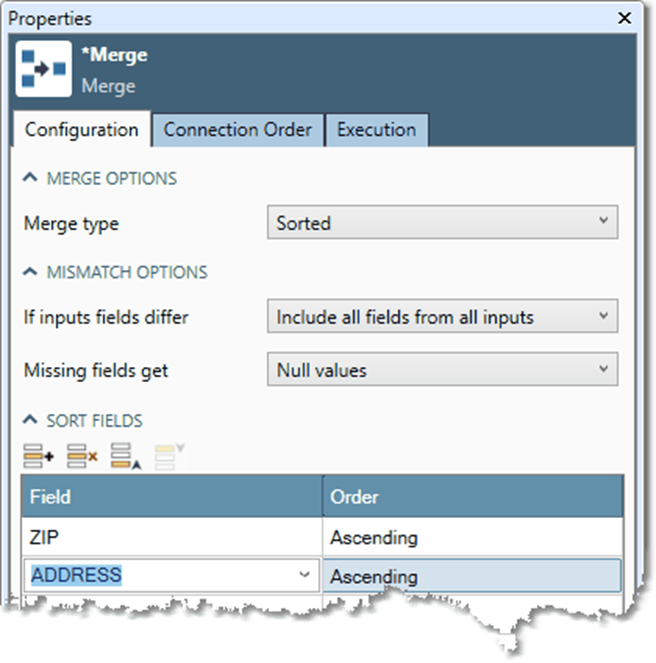
Recognizing that both the L and J outputs are ordered by ZIP/ADDRESS, we change the Left-to-right-merge type to a Sorted-type merge using the ZIP and ADDRESS keys.
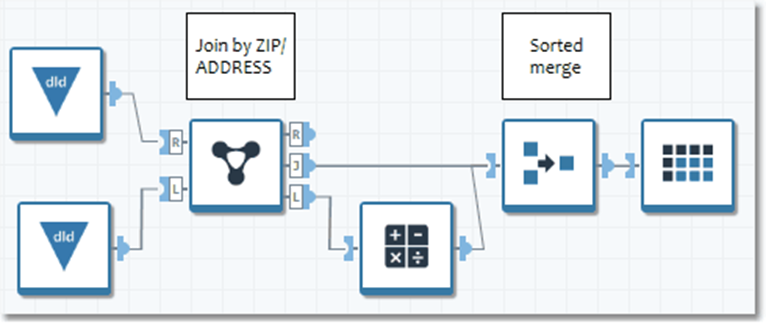
Now you can eliminate the unneeded Sort.