

Overview
The Token Creation tool is used in the first step of textual field parsing. The tool breaks continuous text in a field into separate components called tokens. These tokens can then be processed in the Symbol Creation tool.
For each generated token, the Token Creation tool creates a record consisting of the incoming record's unique ID and the token. (If your data does not have a unique ID field, we recommend that you create one using the Generate Sequence tool.) The process creates record groups—a group of token records for each input record. A record group will contain as many records as there were tokens generated. Record groups with no identified tokens will contain a single record.
Tokens can be identified using one of these methods:
-
Tokens can be delimited by whitespace characters that you specify, and the whitespace characters discarded. Whitespace characters are most often space and tab characters, but can also include other characters such as slashes, parentheses, and underscores.
-
Tokens can be delimited by framing characters that you specify, and the framing characters kept and turned into single-character tokens. Framing characters are most often parentheses and brackets, but can also include other characters such as slashes, braces, and commas.
-
You can define a list of "special-case" strings to be kept whole as single tokens, even if they contain whitespace or framing characters. Do not enclose these strings within quotation marks.
-
Tokens delimited by whitespace or framing characters can be further split using token patterns or regular expressions. Token patterns are useful for splitting text that matches patterns but does not contain a single character where the text should be broken. For example, you might want to split the token 1000ml into 1000 and ml.
-
You can specify phrases to be kept whole or tokens that should be split by adding inputs to the Token Creation tool.
Token Creation tool configuration parameters
The Token Creation tool has one set of configuration parameters in addition to the standard execution options.
|
Parameter |
Description |
|---|---|
|
Input group |
Field that uniquely identifies each original record. All token records from the same input record will belong to the same group. |
|
Input text |
Text field to be split into tokens. |
|
Output token |
If specified, text field in the output record that will receive tokens. This is optional and defaults to new field TOKEN. |
|
Whitespace |
Characters to be discarded from the token values. |
|
Framing |
Characters to be retained as token values. |
|
Token case |
If specified, determines how character case is handled during matching. This is optional and defaults to Case sensitive. |
|
Do not split patterns
|
Patterns (regular expressions) representing text components that should not be split apart. |
|
Break-apart patterns
|
Patterns describing text components that should be separated into tokens. |
|
Output group field |
Outputs the group field. Clear this option if you don’t need the group field. |
|
Output empty token for blank input |
Outputs a single empty token for an empty input (or any input that would otherwise not generate any tokens). Clear this option to output only non-empty tokens. Select this if the token stream will be sent to Symbol Creation or Pattern Match tools. |
|
Non-printing characters are whitespace |
Select to treat all non-printing characters as whitespace, including code points 0-31 and 128-160. |
|
Set output token size
|
Select and specify a size to change the token size to something other than the length of the input field. Do this if you are going to manually change the token values later, and you want to make sure that the token field is big enough, or if you are certain that the tokens will be small, and you want the project to run a little faster. |
|
Include fields |
Fields to be output to downstream tools. |
Configure the Token Creation tool
-
Select the Token Creation tool.
-
Go to the Configuration tab on the Properties pane.
-
Specify Input/Output Fields:
-
Select Input group and select a unique ID field that can be used by downstream tools to reassemble records. This ID will define record groups.
-
If your data does not have a unique ID field, you can create one using the Generate Sequence tool.
-
Select Input text and choose the free-form text field you want to split into tokens.
-
Optionally, you can select Output token and specify an output field to receive the split tokens. By default, a new field named
TOKENreceives the token values.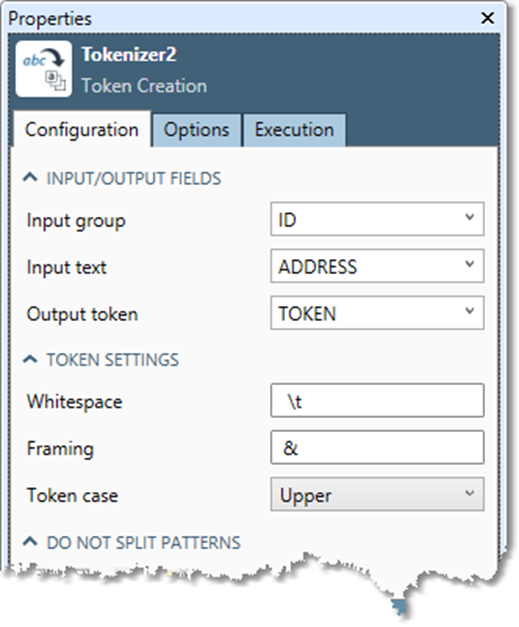
-
-
Specify Token Settings:
-
Enter whitespace characters into the Whitespace box. These characters will be discarded from the token values.
-
Enter framing characters into the Framing box. These characters will be retained as token values.
To specify non-printing or special characters, both whitespace characters and framing characters must use these character sequences:
-
|
Special character |
Sequence |
|---|---|
|
Newline |
\n |
|
Carriage return |
\r |
|
Tab |
\t |
|
Backspace |
\b |
|
Single backslash |
\\ |
|
Form feed |
\f |
You must double the backslash character to specify a single backslash.
-
Optionally, select Token case and specify how character case is handled during matching.
|
Character case |
Description |
|---|---|
|
Uppercase |
Tokens are all forced to |
|
Lowercase |
Tokens are all forced to |
|
Case Sensitive |
Tokens keep original case, and matching to split/keep-together expressions and tables is performed in a case-sensitive fashion. |
|
Case Insensitive |
Tokens keep original case, and matching to split/keep-together expressions and tables is performed in a case-insensitive fashion. |
-
Optionally, select the Do not split patterns grid and specify one or more patterns (regular expressions) that you want to keep whole, even if they contain whitespace or framing characters. For example, you might want to keep together some words that contain spaces or framing characters:
"PO BOX"
"D.C."
"MR."
"DR."
"NORTH CAROLINA"
To break apart hyphenated words, but keep together hyphenated numbers, specify the dash as a framing character and use this keep-together pattern:
d+ '-' d+
To split words at slash except for dates, specify slash as a framing character and use this break-apart pattern:
d{1,2} '/' d{1,2} '/' d{2,4}
You can also specify phrases to be kept whole as an input to the Token Creation tool—see below.
-
Optionally, select the Break-apart patterns grid and specify one or more patterns (regular expressions) describing text components you want separated into tokens.
Tokens matching any pattern are split by extracting the contents of subexpressions (denoted within the pattern by assignment actions) from the token and assigning these to separate tokens. For example, to split tokens such as 1000ml into the amount 1000 and the unit ml, use a pattern of the form:
=(d+) ="ml"
To extend this pattern to handle the units ml, cc, and qt, create a combined pattern. Note that the pattern is enclosed by parentheses so that the = binds to its entirety:
=(d+) =("ml"|"cc"|"qt")
Remember that each sub-token you want to extract must be preceded by an equal sign. Use parentheses to group complex patterns or sequences together.
Patterns are evaluated in the order they appear in the grid. Select ![]()
![]()
![]()
-
Optionally, go to the Options tab, and configure output options:
-
Clear Output group field if you do not need the group field for downstream processing.
-
Clear Output empty token for blank input if you want only non-empty tokens on output. Select if the tokens will be sent to the Symbol Creation or Pattern Match tools.
-
Select Non-printing characters are whitespace to treat all non-printing characters as whitespace, including code points 0-31 and 128-160.
-
Select Set output token size and specify the Token size to change the token size to something other than the length of the input field. You may want to do this if you will manually change the token values later and you want to ensure that the token field is large enough, or if you are certain that the tokens will be small, and you want the project to run a little faster.
-
Select one or more Include fields. Fields on this list will be copied from the Token Creation tool's input to output records, permitting downstream tools to perform processing directly on the token stream while making use of the other fields.
-
-
Optionally, go to the Execution tab, and then set Web service options.
-
Optionally, you can add inputs listing any text components that you want separated into tokens or kept whole. The input can be a file, table, or data stream. It should have one token or phrase per line; the first column of each line is assumed to contain the token or phrase. Connect the input containing the tokens or phrases to the K or S input on the Token Creation Tool:
-
Inputs to K will be read at runtime and interpreted as a set of phrases that would normally be split by the whitespace or framing character sets, but which should be kept whole.
-
Inputs to S will be read at runtime and interpreted as a set of tokens that would normally be kept whole but should be split from the front and back of tokens.
-