

This section provides additional details related to the configuration, creation, and usage of RPDM stub projects generated from RPI.
Creating and configuring RPDM stub project
Once the Data Process Project (DPP) is configured in RPI, generate the stub RPDM project by clicking the option in the configuration menu Click here to generate and save a project stub. Save the file to a location in your local file system that is accessible by RPDM.
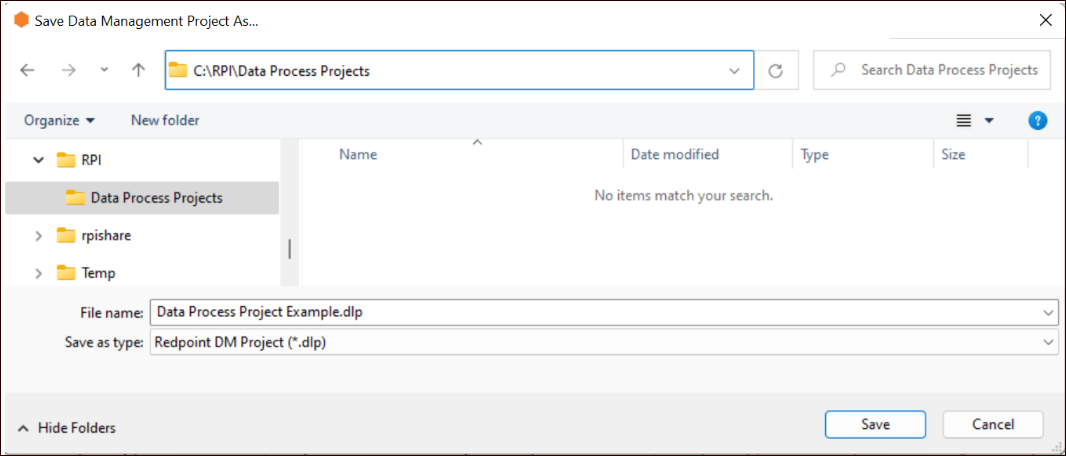
Open RPDM and navigate to the file in the location it was saved in the previous step.
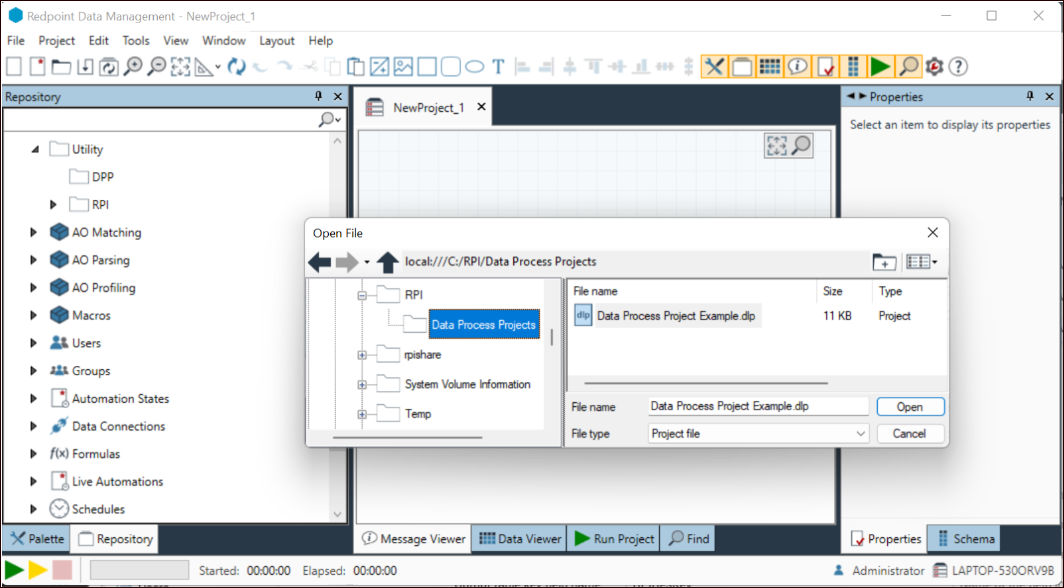
Save the project as the name of the project in the Repository Path of the Data Process Configuration. In this example, the project name is Data_Process_Project_Example and the full path in the RPDM repository is Utility\DPP\Data_Project_Process_Example.
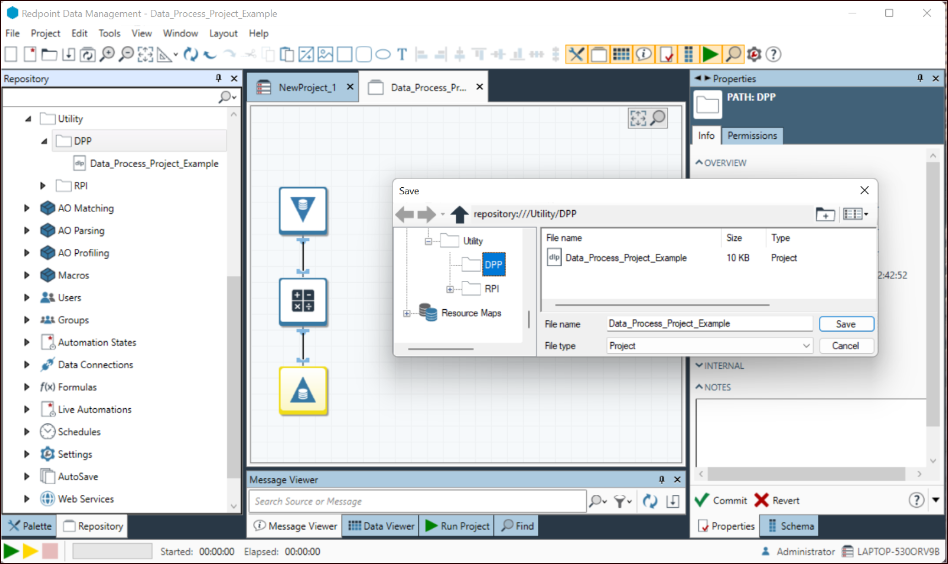
After creating the RPDM project from the stub, additional tools will be included to enhance the functionality to accomplish a given use case. An explanation for how each of these auto-generated tools is configured is available in the next section.
Variables passed to RPDM for RPI
Several variables are automatically generated and passed from RPI to RPDM during the data process execution. There are notes related to each of the values in the table below, but knowledge of RPI is needed to understand how the variable relates to RPI. All of these variables are not required for every DPP use case, but they are provided to RPDM in case they are needed.
The following table provides variable names, sample values, and notes:
|
Variable Name |
Sample Values |
Notes |
|---|---|---|
|
|
|
GUID of the DPP in RPI. |
|
|
|
Name of the DPP activity in RPI. |
|
|
|
RPI tenant client ID. |
|
|
|
GUID of the interaction in RPI. Populated if DPP is run in an interaction. |
|
|
|
Reference for the source temp table that is passed from RPI. |
|
|
|
GUID of the RPI workflow association ID found in the RPI operations database. |
|
|
|
RPI workflow ID which the DPP is being executed as a part of. |
|
|
|
RPI Dataflow ID which the DPP is being executed as a part of. |
|
|
|
Name of the output temp table that RPI will reference when a DPP is used in an audience for segmentation/bandings. |
|
|
|
RPDM data connection name that is defined in RPI in the system configuration. |
|
|
|
RPDM schema that is defined in RPI in the system configuration. |
|
|
|
Name of the database key that is defined as the resolution of the audience definition used in the audience executing the DPP. |
|
|
|
Flag to indicate if the workflow is being executed in test or production mode in RPI. |
|
|
|
Custom parameter that is defined in the configuration of DPP in RPI. The value is set when you configure a data process project in an audience or interaction. |
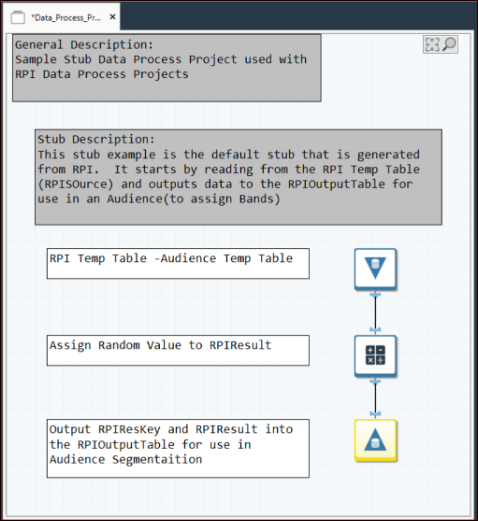
RPDM sample stub project
This is the sample stub that is generated from RPI upon creation of the DPP. This is the baseline from which additional processing steps should be added. This stub project is assumed to be used within an RPI audience, and that is why the output table is being used to associate the records to a banding. It is not required to write to the output table. There are various use cases where that is a logical approach; most are related to advanced topics that are not covered in this document.
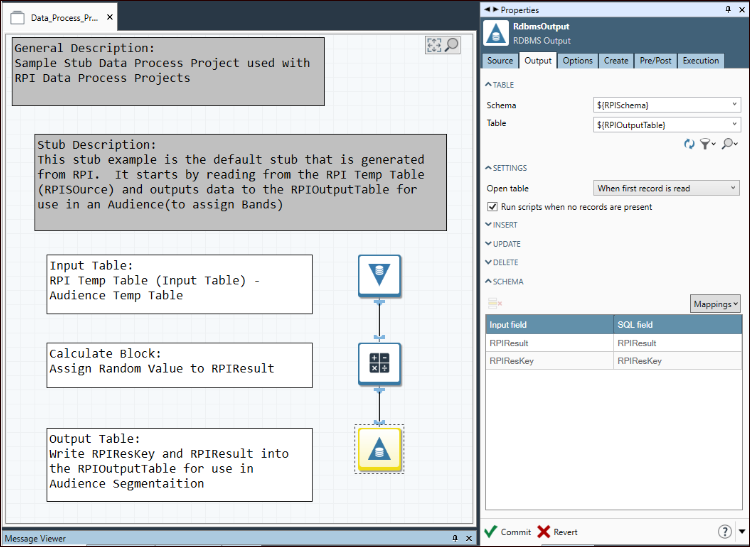
Input table (RPI temp table)
The RPI stub project RDBMS input table (temp table) consists of the ResolutionID as well as the OfferHistory attributes defined within the audience definition used in the associated audience/interaction. The variable RPISQLSource contains the temp table as well as the FROM portion of select statement (example value: FROM [dbo].[Dataflow_91] r WHERE r.[DataflowID] = 91). The WHERE clause may also contain criteria such as output name if a specific output was defined as the input to the data process within an interaction.
This table is used as a source of resolution keys to assign bands in audiences, and subsequently the output table would be used to store the associated values. Also, the use of the ResolutionID can be used to join to other tables and perform associated logic for a given use case.
Calculate block
The sample calculate block merely assigns a random number to the RPIResult field in the stub project. In a real-life example, the RPIResult field values would be the result of processing configured for a given use case. In our example, this would be where we store the numeric model score to be assigned to each customer record processed by the project.
Output table
The RPI output temp table is passed in the variable RPIOutputTable and is used when you are implementing the data project within an audience, and you are using bands to define segments. This table is used in the RPDM stub project RDBMS output. This is preconfigured with two fields, the names of which are defined when the RPI data process is created upon enabling the use in audience option. When the data process uses bands which are defined as outputs to the data project within the audience, the RPI input table is joined to the RPI output table on the resolution key, and the RPIResult field is used to store the value that will be used by the banding to determine which resolution key is associated to what banding. This output table will only contain these two fields, as it is only used for the purpose of defining bands.