Redpoint Interaction (RPI) can handle one-to-many (1:M) joins, and they work as one would expect when using selection rules. However, when you try to use a value from the many side of the join for personalization or extraction, you can get inconsistent results. RPI will return a value, but there is no criteria used to determine which value from the many side to use, so you may not get the results you are expecting.
There are multiple ways to handle this. Each has different applications that it may be more appropriate for, so you need to understand your expected outcomes to determine the best option to use for your situation. As additional options are documented, they will be added to the list below:
Below are the detailed pages related to features in RPI that can be used to make this data available for extraction and use in personalization:
In these pages, we use the following reference data model to illustrate the data structures and the way the data may be stored in a one-to-many data model.
Data related to example
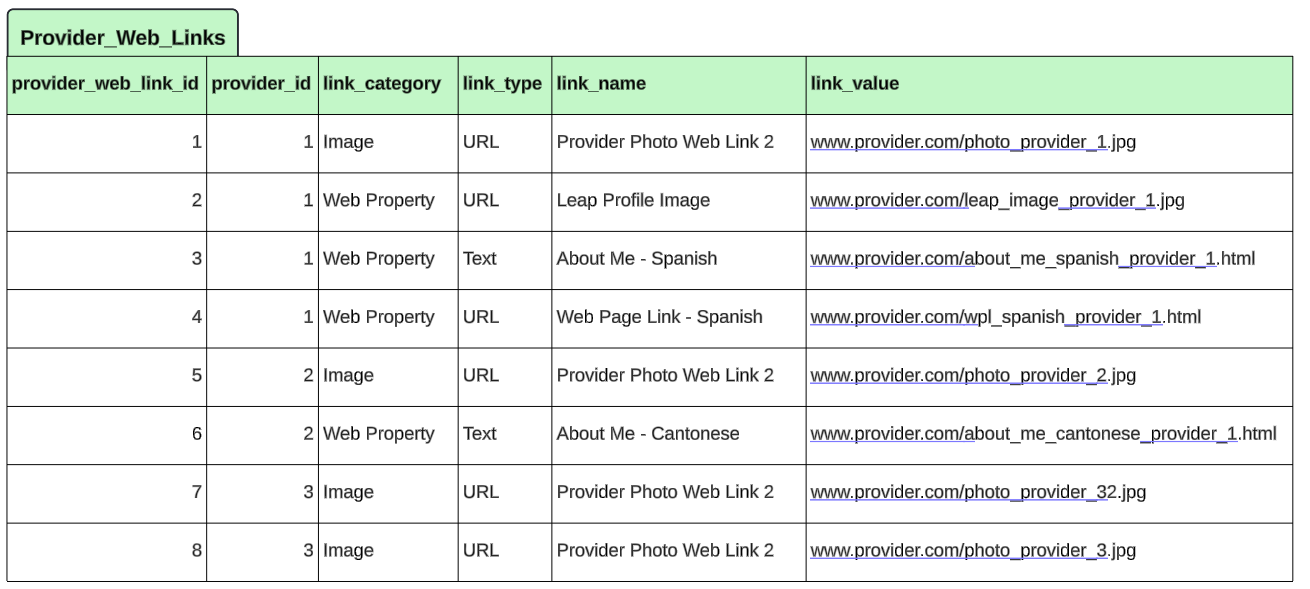
In the following sections we will review the data that will be used to illustrate the various features and options we have to support using data from the many side of a one-to-many relationship for extraction or personalization within RPI. We’ll start with a simple entity relationship diagram (ERD) below, which depicts a one-to-many (1:M) relationship between Provider and Provider Web Links.
The following are example data sets for each of the tables in the ERD above. That set of data will be used in the detailed feature use cases in this section. An illustration of the data in table format is listed below.
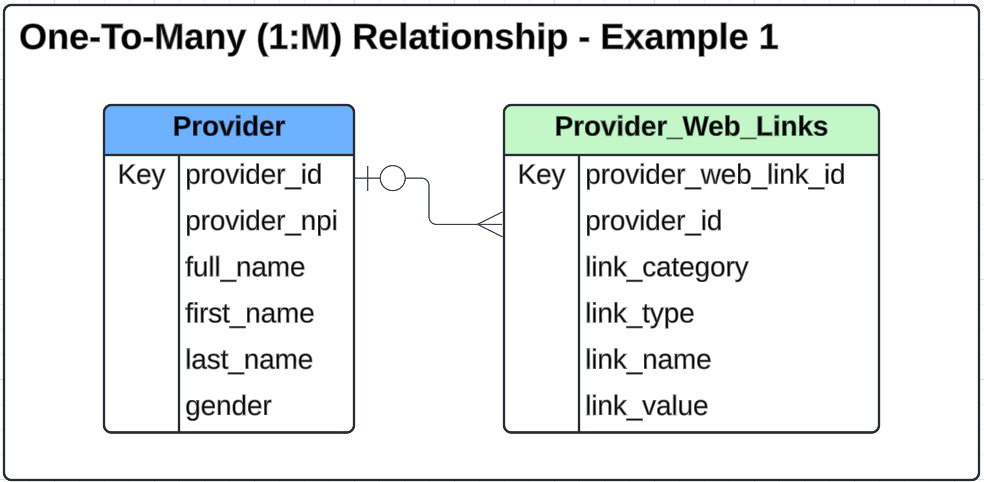
Provider table
The provider table contains unique records for each provider based on Provider ID. There are some additional fields including PII to round out the data.
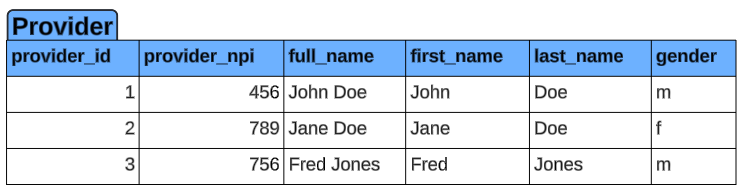
Links table
The links table can have many records for a single provider_id and represents the many side of the ERD in support of the features we will illustrate. The column called link_id is the primary key in this table. The reason we included this was to provide a use case where all other fields are duplicated besides the link value. Provider ID 3 has two records that are all the same but have different provider_web_link_ids and link_values. They are intended to show what happens when using various features when the data is loaded incorrectly. In those cases you may not get errors in RPI, but you will potentially get unexpected results. Each of the approaches above will address how this bad data will affect the results or process.