Overview
The counterpart of the Merge tool is the Splitter tool. After the Splitter tool splits one record stream into many, the Merge tool combines multiple streams into one. For each Splitter type, there is a companion Merge type that precisely reverses the splitting to recreate the original record order.
The Merge tool combines the records of multiple inputs into a single output. It uses one of several merge types to combine the records. Each merge type produces different tradeoffs between performance and guarantees of record order.
|
Merge type |
Description |
When to use |
Performance |
|---|---|---|---|
|
Reads all records from the leftmost input, then all the records from the next input, until each input has been completely processed. Note that the Left-to-Right merge type uses a lot of extra temp space and can reduce performance. |
Use when left-to-right record order must be preserved. |
Poor, as records for all but the leftmost inputs must be delayed. |
|
|
Greedy (default) |
Reads the next available record from any input, in no particular order. |
Use when record order is not important. |
The best possible for a wide variety of input streams. |
|
Reads records in order determined by a "sequence field" (a sequential number that determines record order). Each input must be in sequence-field order, and sequence numbers must appear exactly once in all inputs. |
Use to reassemble records that were originally in sequence order but were split for processing purposes. |
Very good for records that were ordered before splitting. |
|
|
Reads records in order determined by a set of key fields. Each input must already be ordered according to the sort keys. |
Use when records from multiple sorted inputs need to be combined. |
Not as good as Sequence, but more flexible. |
|
|
Reads a record from each input, then cycles around to read another record from each input. |
Use when merging streams split by the Splitter tool's round-robin technique. |
Good when used in conjunction with the Splitter tool. |
Merge tool configuration parameters
The Merge tool has one set of configuration parameters in addition to the standard execution options.
|
Parameter |
Description |
|---|---|
|
Merge type |
Specifies how the multiple inputs are to be combined. This is optional and defaults to Greedy. |
|
If input fields differ |
Determines how inputs with different field sets are treated. This is optional and defaults to Include all fields from all inputs. |
|
Missing fields get |
Determines the values that will be used for missing fields. This is optional and defaults to Null values. |
|
Sequence field |
Required for Sequence merge types. Specifies the numeric field that will contain a sequence of numbers starting at zero and incrementing by one. It is used to establish an absolute ordering among all records. |
|
Sequence start |
Specifies the starting sequence value for Sequence Merge types. This is optional and defaults to 0. |
|
Field |
Required for Sorted Merge types. Specifies the input field containing the sorted key. |
|
Order |
Required for Sorted Merge types. Sort order for Sorted Merge types; either Ascending or Descending. |
Configure the Merge tool
-
Select the Merge tool, and then go to the Configuration tab on the Properties pane.
-
Select a Merge type from the list:
-
Greedy (default)
-
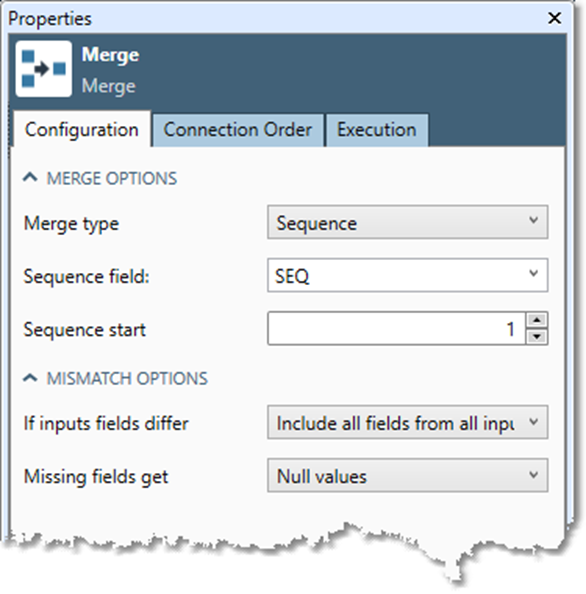
If you selected Sequence merge type, specify the Sequence field and assign a Sequence start value.
-
In the MISMATCH OPTIONS section, specify what to do If input fields differ. Options are:
-
Include all fields from all inputs: for example, you might want to combine several customer lists, some of which have additional information about the customer (like age or gender).
-
Use the common subset of fields: select this option to create a table containing only the subset of fields that are shared across all input files. For example, in mailing-list processing, you may be interested in only the NAME, ADDRESS, CITY, STATE, and ZIP fields of your data. Field names that do not appear in all input tables are dropped from the output.
-
Report an error: select this option if you expect all of your inputs to have the same field names, and you want to know if there is a misnamed or missing field.
-
-
If you select the Sorted merge type, select the sorted Field or Fields and specify sort Order.
-
If you select Include all fields from all inputs, the Missing fields get option is available.
-
Choose Null values to assign null values to missing fields, or Default values to assign the following non-null values.
|
Field type |
Default value |
|---|---|
|
Text |
"" |
|
Fixed-point |
0 |
|
Floating-point |
0.0 |
|
Date |
1 Jan 1600 |
|
Time |
00:00:00 |
|
DateTime |
00:00:00 1 Jan 1600 |
|
Boolean |
False |
|
Binary |
empty |
-
If you specified a Left-to-right or Round-robin Merge type, you may optionally select the Connection Order tab and adjust the order of input connections.
-
The Left-to-right option reads all records from the leftmost (or topmost) input, then all the records from the next input, and so on until each input has been completely processed. "Left" corresponds to the first input connection; thus connection order determines which records are read first.
-
The Round robin option reads records split using the Splitter tool with a round-robin split type, which assumes that data inputs and outputs are processed in the same order. If the connections are ordered differently in the Splitter and Merge tools, the data stream will be reassembled in a different record order.
-
-
Optionally, go to the Execution tab, and then set Web service options.
Left-to-right merge type
Choose this merge type when it is important to preserve the order of inputs. For example, if you are reading from several lookup tables but want to give priority to entries in the left-most tables, you would use Merge with a Left-to-right setting, so that all of the left input records come first. Don't use the Left-to-right merge type unless you need it, because it will cause everything on the non-leftmost inputs to wait or spool to disk while the leftmost input is processed. This uses a lot of extra temp space and reduces performance. Choosing a merge type other than left-to-right will greatly reduce temp space usage.
Greedy merge type
Also termed an "unordered union." Use this technique when you want the best performance and don't care about record order (either record order doesn't matter, or you're going to re-sort it later anyway). The Greedy merge will read whatever records are available from any input and reduces the tendency for some inputs to wait for others. This is useful when records are split and recombined but aren't in any particular order.
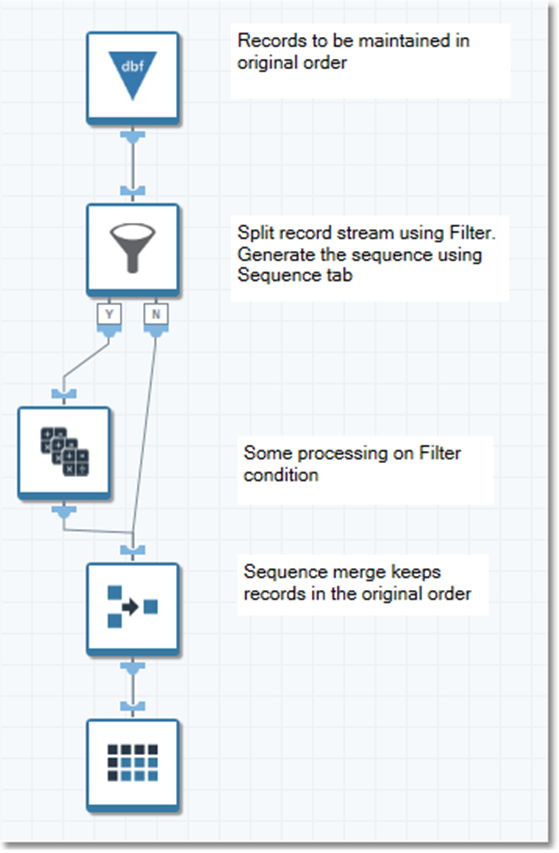
Sequence merge type
Use this technique when you want good performance and need to keep records in strict order. The Sequence merge keeps track of the next expected sequence number, and looks for that record on the inputs. You must assign the sequential numbers before they are split (using the Number Records tool or the Sequence tab of the Filter tool), so that the combined set of records has the correct set of sequence numbers. See sample project filter_merge_sequence for an example.
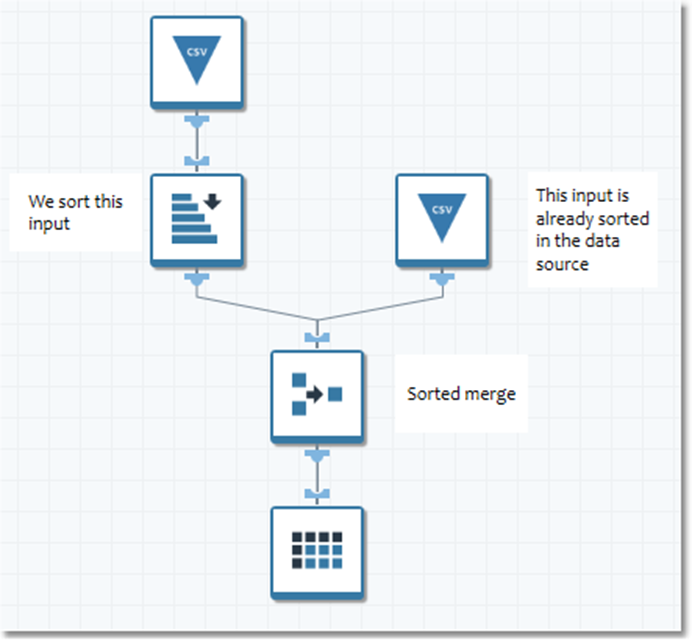
Sorted merge type
Use this merge type when you want to merge two or more record streams that are already sorted by some keys, but those keys aren't necessarily sequential. This avoids re-sorting the merged stream, increasing performance.
Round-robin merge type
Use this merge type when you want to merge record streams that were split using the Splitter tool with a round-robin split type. This is typically done to parallelize CPU-intensive processes like CASS. The round-robin merge type reverses the split.