

You can initiate the testing of the current audience using the Tests toolbar button. This button is only available when no outstanding changes exist within the audience, and when it is valid. On selecting the button, a menu is displayed. If the audience has been tested previously, up to the 100 most recent test instances are listed (with the most recent instance displayed first).
Note that each test instance has its own separate Audience (instance) ID and temporary Workflow (instance) ID.
The option to start a new test is always provided.
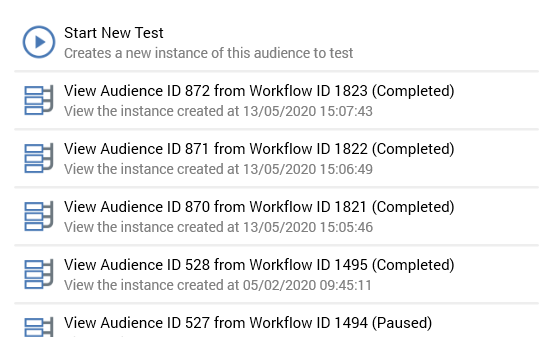
Selecting Start new test displays the Start new test dialog:
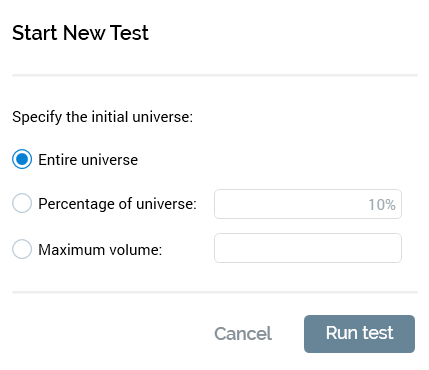
Three radio buttons allow you to specify the size of the initial data set against which the rules articulated in the audience will be run:
-
Entire universe: this option is selected by default. If chosen, all records available in the current audience definition’s universe will serve as the input to the audience.
-
Percentage of universe: if this option is selected, a specified, random percentage of the total available universe will be selected, and the rules in the audience executed against it. Percentage… defaults to 10, and a value must be provided if the radio button is selected (up to a maximum of 100%).
-
Maximum volume: if this option is selected, up to the specified maximum volume of records will serve as the test data set (if the specified value is greater than the size of the universe, the whole universe will be used). If the radio button is selected, a value between 1 and 9,999,999 must be supplied.
Selecting a previous test instance displays the existing instance in the Audience Instance Viewer. If executing a new test, you can watch as the audience’s rules are executed. In both cases, you can view the results of the audience’s test execution in the Results Window.
If the test was executed against a percentage of the universe or a maximum volume of records, the watermark shown at the Audience Instance Viewer, which displays the name of the audience being tested, is augmented with the percentage or actual number of records that served as the test’s input data set.
If the audience contains an auxiliary selection rule, it is executed to determine a list of keys that match the rule’s criteria, which is written to a temporary table. This table can then be used to join to data warehouse tables to identify matching data warehouse records which will serve as the audience’s output(s).
If you run a test at an audience that contains an auxiliary selection rule, and sufficient joins do not exist to link the resolution levels of the auxiliary rule and the audience’s definition, an error occurs.
If you attempt to run an audience test when a restricted audience definition has been selected, a Permission Denied dialog is displayed, and an error is thrown. The same restriction also applies when the audience contains a:
-
Filter, suppressions or split block configured with a selection rule using a restricted resolution level.
-
Cell list block configured with a cell list using a restricted audience definition or configured with an audience using a restricted audience definition or configured with a block as above.
-
Audience block configured with an audience using a restricted audience definition or configured with a block as above.
If the audience’s audience definition is defined as producing validation files, these can also be accessed at the Results Window, providing you with an accurate impression of the audience’s segments during interaction execution.
If the audience definition is defined as producing an audience waterfall report in Test mode, the report is available at the Results Window’s Files tab.
For further details please see the Audience Instance Viewer and Results Window documentation.
When the current RPI installation is using a SQL Server data warehouse or auxiliary database, if the system is unable to connect when running an audience test (for example due to the database server not being found, the database login failing (due e.g. to the database being detached) or because of a deadlock), a series of attempts to reach the database are made (over a maximum of a 10-minute period). After this time, the series of retries are abandoned. All retry details are logged to the server log.
If the audience contains a data process block, if its Data process project's Use results in audience property is unchecked, the RPDM project that it represents is executed independently of the continued execution of other blocks within the audience.
If Use results in audience is checked, you can leverage the data process project's Output table result field values in the following contexts:
-
Output sampling (Cap on result field order, Nthing on result field order)
-
Output bands (Discrete, Value range, Relative date)
If no output(s) have been configured at the data process block, a single output, named in accordance with the block's name, is created.
The passing of project parameters to the RPDM project is supported (values can be specified in the block's Project tab). The passing of additional, unnecessary, parameters does not cause a failure to occur.
Note that the following data process project properties must match those at the RPDM project, or the audience will fail:
-
Repository path
-
Output table key field name
-
Output table result field name
When a model scoring block executes in an audience. RPI calls the AML service to execute the model with which the block’s model project is configured. This returns a model score for each targeted record. Records can then be classified by band.