

Overview
Redpoint Data Management v9.6.1 introduces a next-generation set of database providers that were rewritten to be more robust and performant. The next-generation data providers have also greatly simplified configuration options with optimized defaults. Refer to RDBMS database providers for a table that delineates next-generation data provider availability.
This topic provides information about:
-
Legacy data provider options (which remain unchanged in RPDM v9.6.1)
Next-generation data provider options
new in 9.6.1
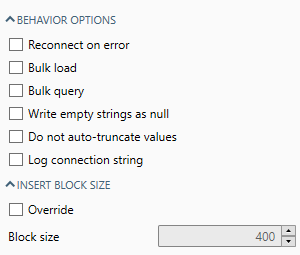
The simplified configuration options available for next-generation data providers are described in this section. Not all options apply to all providers.
-
For tools without a data connection (i.e., inline configuration), all options are configurable at the tool level.
-
For tools with a data connection, options must be set in the data connection and cannot be overridden at the tool level. The exception is Block size, which can override the provider default at the tool level.
Both bulk load and query operations can yield substantial performance gains when processing large volumes of records, often achieving 5–10x improvements. However, these benefits come with an initial startup cost, making them most effective beyond a certain data volume threshold.
The following table describes each of the available options.
|
Option |
Description |
|---|---|
|
Reconnect on error |
When enabled, attempts to reconnect to the database when an error has caused a disconnect. |
|
Bulk load |
Enables bulk load support. This option is only available if you’ve selected a database provider that supports bulk load (refer to RDBMS providers for availability). Refer to RDBMS providers: Azure for important information about using bulk load in Azure Synapse. |
|
Bulk query |
Enables bulk query support. This option is only available if you’ve selected a database provider that supports bulk query (refer to RDBMS providers for availability). Refer to RDBMS providers: Azure for important information about using bulk query in Azure Synapse. |
|
Write empty strings as null |
If selected, empty text strings will insert as |
|
Do not auto-truncate values |
Auto-truncate normally trims down values to fit into the size of the target column in the database. If this option is checked, too-long or out-of-range values will cause an error. |
|
Log connection string |
When this option is enabled, the connection string is logged to the Canvas Log/Message Viewer.
|
|
Override |
Overrides the provider default block size. |
|
Block size |
This setting only applies to writing and is ignored for bulk loaders. For non-bulk loaders, increasing Block Size may improve performance, but will increase the tool's memory requirements. With JDBC data connections, specifying a large block size for a table whose row size is large may require you to increase your JVM memory setting. |
Non-bulk next-generation data providers always implicitly demarcate transaction boundaries using blocks.
This departs from the legacy data providers, which expose the Transaction per block option: when enabled, each block is wrapped in a transaction; when disabled, the entire operation is effectively performed in a single transaction.
While the Transaction per block option is a performance optimization, it allows some control over the RDBMS Output tool’s commit/rollback behavior.
For example, consider a scenario in which 2,000 records are inserted with a block size of 500. The first two blocks are inserted without incident, but a constraint is violated while inserting the third block. In that case, the first 1,000 records are inserted to the database, while the remainder are not.
Non-bulk next-generation providers now mandate these transaction per block semantics, principally because the “single massive transaction” model can have dire performance implications for the database itself, given the record volume Data Management often handles. Note, however, that next-generation bulk providers are non-transactional.
Legacy data provider options
The RDBMS Input and Output tools both have Options tabs.
Not all options are available in both tools, and some options apply only to certain data connection types. In some cases you may need to select Override to view all options. The tables below lists the options and their meanings in each tool.
Scripting options
|
Option |
Meaning |
|---|---|
|
Use TRUNCATE TABLE to clear tables |
If selected, clears tables using |
|
SQL quote |
When a table or column name is a reserved word in SQL, or contains "special" characters, this delimiter character will be added when creating SQL scripts. Defaults to double-quote. |
|
SQL separator |
When creating an SQL script in which both table and column are used, (or database and table), this character will be inserted between them. Defaults to period. |
|
Use scripting for create/drop operations |
When automatically creating tables during execution (because they don't yet exist), use SQL scripting instead of the connector's programming interface. This is sometimes necessary because of flaws in the available database drivers. |
|
Quote mixed-case |
Accommodates different database standards for handling names. Options are Default, Yes, No. |
|
Quote in API |
Accommodates different database standards for handling table/column names. Options are Default, Yes, No. |
Performance options
|
Option |
Meaning |
|---|---|
|
Read type (RDBMS Input)
|
The optimal table loading interface may vary between connectors and databases. For RDBMS Input tools, these settings apply only when temporary tables are being used for dynamic query.
|
|
Block size |
The number of rows to retrieve in each Fetch operation, or the number of rows to Increasing Block Size may improve performance, but will increase the tool's memory requirements. With JDBC data connections, specifying a large block size for a table whose row size is large may require you to increase your JVM memory setting. |
|
JDBC block size |
Improves internal efficiency of JDBC inserts and reads. Should be smaller than Block size. Increasing JDBC block size may improve performance, but will increase the tool's memory requirements. The incremental performance improvement diminishes sharply at larger values. The default setting of |
|
Transaction per block |
Surrounds a block |
|
Record binding |
Indicates whether the array of data exchanged between the database and Data Management is ordered by rows or by columns. This is determined by the database; each one has a preferred binding order. Using the predefined database provider templates is the best way to ensure that the correct insertion methods and binding orders are chosen. JDBC data connections ignore this setting. |
|
Max value size |
Configure this option for ODBC connections, when reading unbounded field types such as ODBC providers have been deprecated in Data Management, and the ODBC drivers may not be supported in future versions. |
|
Use threading |
Allows some database processing to be done in the background, which can reduce the elapsed time for large insert operations. This option is ignored for chunk update/delete operations. |
|
Use transaction block |
Surrounds a block |
Behavior options
|
Option |
Meaning |
|---|---|
|
Treat Unicode as Latin-1 |
RDBMS Input: converts Unicode (for example, RDBMS Output: when a table is created or a table creation script is generated, columns are created with type varchar instead of |
|
Treat empty text as null when loading |
If selected, empty text strings will insert as |
|
Stream objects |
Some database objects (such as |
|
Larger than |
Threshold for streaming large database objects. |
Logging options
|
Option |
Meaning |
|---|---|
|
Connection string |
Writes the connection string (command used to connect to a database) to the log. Useful for troubleshooting connection problems. |