

Overview
Should I use Join or the Join2 tool?
-
If you need inequality relations between keys, use the Join2 tool.
-
When the Table input is small enough to load into memory, use the Join2 tool. It is much faster because it does not sort the inputs.
-
For very large Table data that will not fit in memory, use the Join tool.
-
If you need the One-to-one Join type, you must use the Join tool.
Join
The Join tool accepts two inputs—Left and Right—and matches records from both inputs on a single key field or column. The tool combines the matched Left and Right records into a single "wide" record containing all fields from both inputs. This function is similar to an SQL join. However, Data Management's Join tool contains numerous extensions that make it suitable for a wider variety of processing tasks. In particular, the Join tool always produces three outputs, any or all of which can be connected:
-
The Left Outer output contains all of the Left input records that do not appear in the Join output.
-
The Join output contains all of the matched Left and Right records.
-
The Right Outer output contains all of the Right input records that do not appear in the Join output.
The simultaneous availability of all three outputs simplifies many tasks. For example, suppose you are joining two tables that should be related on a common key, and the documentation for the data claims that all records are related. You would like to join the two tables and process them, but you also want to flag any exceptions to the documented rule—finding all of the records from both sources that didn't match. You can accomplish this by sending the Left Outer and Right Outer outputs to files or processing them further for reporting purposes.
For some typical uses of Join, see:
Join tool configuration parameters
The Join tool has one set of configuration parameters in addition to the standard execution options:
|
Parameter |
Description |
|---|---|
|
Join type |
The Join algorithm to be performed. This is optional and defaults to Cartesian. |
|
Left field |
List of Left input fields on which to perform the Join. |
|
Right field |
List of Right input fields on which to perform the Join. These must be compatible with those of the Left field. |
|
Join output |
List of fields to be included in output. You can Select them individually, or choose from Select all, Select none, Select non-conflicting, Rename conflicting, or Remove non-existent. All fields in the output record must have unique names. |
|
Automatically select new fields |
If selected, any upstream field that is not specified in Rename fields will be selected automatically on output. |
|
No warning on empty join |
If selected, suppresses the warning that would normally appear when no Join fields are specified. |
Configure the Join tool
-
Select the Join tool, and then go to the Configuration tab on the Properties pane.
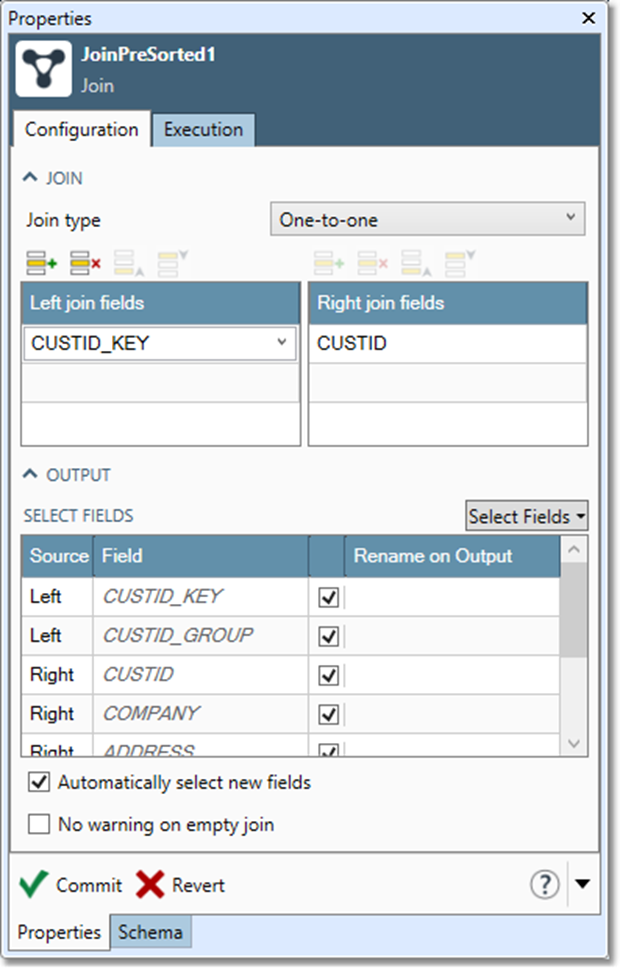
-
Select the Join type box to select the variety of Join you want to perform:
|
To… |
Use this Join type… |
|---|---|
|
Emulate an SQL query join (see Joining tables from separate databases) |
|
|
Perform cross-table assignments when there is either a one-to-many or many-to-one relation between the Left and Right tables (see Assigning values from records in one table to matching records in another table) |
|
|
Perform cross-table assignments and there is a one-to-many relation between the Left and Right tables |
|
|
Perform cross-table assignments and there is a many-to-one relation between the Left and Right tables |
|
|
Match two tables on a single field such that no Left record gets matched to more than one Right record (and vice versa) |
|
|
Verify a one-to-many relation between the Left and Right inputs (see Using Join to verify relational integrity) |
|
|
Verify a many-to-one relation between the Left and Right inputs (see Using Join to verify relational integrity) |
|
|
Find all the Right records that match any Left record (see Finding all the records in one table that match records in another table) |
|
|
Find no more than one match for each unique join key value |
-
In the Left field box, type or select one or more fields from the Left input records that you want to match against the Right input records.
-
In the Right field box, type or select the one or more fields from the Right input records that you want to match against the Left input records.
The left and right fields to be joined must be of the same type. If you are joining large record sets, and one of them is unique on the join keys but the other is not, you should connect the non-unique input to "L" and the unique input to "R".
-
Optionally, choose the fields you wish to output: select them individually, or select Select fields to choose from:
-
Select all
-
Select none
-
Select non-conflicting
-
Select highlighted
-
De-select highlighted
-
Toggle highlighted
-
Rename conflicting
-
Remove non-existent
-
All fields in the output record must have unique names. You can also add a common prefix or suffix to all field names by using the Rename tool on one of the inputs before it enters the Join tool. This makes the fields easy to identify and split apart.
-
To automatically select new fields that can be added when you change the input to the Select tool, check the Automatically select new fields box. This is useful if you are creating a project for repeated use and think the data you are processing may have fields added in the future.
-
Optionally, go to the Execution tab, and then set Web service options.
Types of Join
Data Management supports several "flavors" of Join, including the Cartesian Join used by SQL. The others are special cases designed to for data transformation rather than data query: One-to-one Join, Left Unique Join, Right Unique Join, and Left and Right Unique Join.
To understand the need for the additional join types, think of what you would normally do to cross-process the records of two tables, using a scripting database language. Typically, you would:
-
Loop through the records of the first table.
-
For each record find matching records in a second table.
-
Perform some operation on the pairs of matched records (such as assigning fields, or inserting or removing records).
In Data Management, you use Join for these kinds of operations. The variants of Join support a variety of processing models—sometimes you want to operate on all combinations of matches (Cartesian join), sometimes you want a one-to-one match between the records of the two tables, and sometimes you only want the first one of each group.
The advantages of using Join instead of a scripting language are:
-
It’s much faster
-
You don't have to write any code
Join is a multipurpose tool for linking two tables on a relation field. Once the tables are linked, you can perform operations between the matched records of the two tables. This is perhaps the most tricky concept in all of Data Management: you use Join anywhere you want to co-process two tables linked by a relation field.
Cartesian Join
In a Cartesian Join, Data Management finds all matching Right records for every Left record and outputs the resulting "wide" record. This is the standard join used by SQL. Note that if there are M Left records and N Right records, this can produce M * N output records.
For example, the following Left and Right inputs, when joined on the first column.
|
Left |
Left |
Right |
Right |
|---|---|---|---|
|
A |
1 |
A |
10 |
|
A |
2 |
A |
20 |
|
B |
3 |
A |
30 |
|
C |
4 |
B |
40 |
will produce this Join output.
|
Join |
Join |
|---|---|
|
A |
1 |
|
A |
1 |
|
A |
1 |
|
A |
2 |
|
A |
2 |
|
A |
2 |
|
B |
3 |
and will produce these Left Outer and Right Outer outputs.
|
Left Outer |
Left Outer |
Right Outer |
Right Outer |
|---|---|---|---|
|
C |
4 |
|
|
One-to-one Join
In a One-to-one Join, Data Management finds a matching Right record for every Left record, outputs the resulting "wide" record, and then advances both Left and Right inputs to the next record. The result is that each Left and Right record will match only once (or not at all). This is useful when you want to cross-assign field values from one table to another, but you want to avoid the multiple matches per record caused by the Cartesian join type.
Another way to think about the one-to-one join is with the "zipper" analogy. The Left and Right tables are first sorted by the join key. Then they are conceptually lined up side-by-side like halves of a zipper. The zipper is then "zipped up", but only teeth with matching keys are allowed to connect. The other teeth are discarded. You can see by this analogy that each left record (i.e. tooth) can only match one right record.
For example, the following Left and Right inputs, when joined on the first column.
|
Left |
Left |
Right |
Left |
|---|---|---|---|
|
A |
1 |
A |
10 |
|
A |
2 |
A |
20 |
|
B |
3 |
A |
30 |
|
C |
4 |
B |
40 |
will produce this Join output.
|
Join |
Join |
|---|---|
|
A |
1 |
|
A |
2 |
|
B |
3 |
and will produce these Left Outer and Right Outer outputs.
|
Left Outer |
Left Outer |
Right Outer |
Right Outer |
|---|---|---|---|
|
C |
4 |
A |
40 |
Left Unique Join
In a Left Unique Join, Data Management first creates a "unique" list of Left records and discards all duplicates (sending them to the Left Outer output). It then matches the unique list of Left records to the Right records and outputs the resulting set of "wide" records. All non-matching Left and Right records are sent to their respective Outer outputs.
Consider the following example. The Left and Right inputs are joined on the first column using a Left Unique join. Note that the first Left record (A,1) is joined to all the "A" records of the Right input, but the second Left record (A,2) is skipped.
|
Left |
Left |
Right |
Right |
|---|---|---|---|
|
A |
1 |
A |
10 |
|
A |
2 |
A |
20 |
|
B |
3 |
A |
30 |
|
C |
4 |
B |
40 |
will produce this Join output.
|
Join |
Join |
|---|---|
|
A |
1 |
|
A |
1 |
|
A |
1 |
|
B |
3 |
and will produce these Left Outer and Right Outer outputs.
|
Left Outer |
Left Outer |
Right Outer |
Right Outer |
|---|---|---|---|
|
A |
2 |
|
|
|
C |
4 |
|
|
Right Unique Join
In a Right Unique Join, Data Management first creates a "unique" list of Right records and discards all duplicates (sending them to the Right Outer output). It then matches the Left records to the unique list of Right records and outputs the resulting set of "wide" records. All non-matching Left and Right records are sent to their respective Outer outputs.
Consider the following example. The Left and Right inputs are joined on the first column using a Right Unique join. Note that the first Right record (A,10) is joined to all the "A" records of the Left input, but the second and third Right records (A,10 and A,20) are skipped.
|
Left |
Left |
Right |
Right |
|---|---|---|---|
|
A |
1 |
A |
10 |
|
A |
2 |
A |
20 |
|
B |
3 |
A |
30 |
|
C |
4 |
B |
40 |
will produce this Join output.
|
Join |
Join |
|---|---|
|
A |
1 |
|
A |
2 |
|
B |
3 |
and will produce these Left Outer and Right Outer outputs.
|
Left Outer |
Left Outer |
Right Outer |
Left Outer |
|---|---|---|---|
|
C |
4 |
A |
20 |
|
|
|
A |
30 |
Left and Right Unique Join
In a Left and Right Unique Join, Data Management first creates "unique" lists of the Left and Right records and discards all duplicates (sending them to the Left Outer and Right Outer outputs, respectively). It then matches the unique list of Left records to the unique list of Right records and outputs the resulting set of "wide" records. All non-matching Left and Right records are sent to their respective Outer outputs.
Consider the following example. The Left and Right inputs are joined on the first column using a Left and Right Unique join. Note that the first Left record (A,1) is joined to the first Right record (A,10), but all the other "A" records on the Left and Rights inputs are skipped.
|
Left |
Left |
Right |
Right |
|---|---|---|---|
|
A |
1 |
A |
10 |
|
A |
2 |
A |
20 |
|
B |
3 |
A |
30 |
|
C |
4 |
B |
40 |
will produce this Join output.
|
Join |
Join |
|---|---|
|
A |
1 |
|
B |
3 |
and will produce these Left Outer and Right Outer outputs.
|
Left Outer |
Left Outer |
Right Outer |
Left Outer |
|---|---|---|---|
|
A |
2 |
A |
20 |
|
C |
4 |
A |
30 |
Join2
The Join2 tool is similar to the Join tool, but it can do some things that the Join tool cannot, and vice-versa. The Join2 tool loads records from the "Table" input into memory, and then matches records on the "Data" input according to the join keys and relations. An input Data record may match one or more Table records, and each such match results in a combined record being sent to the "Join" output. An input Data record that matches no table records is sent to the "Unmatched" output.
Like the Join tool, the Join2 tool accepts a list of keys to Join on; however, it allows inequality specifications in addition to equality, for example.
|
Data key |
Relation |
Table key |
|---|---|---|
|
|
= |
|
|
|
<= |
|
This is interpreted as "a given Data record matches every Table record where Data.TRANS_ID = Table.TRANSACTION and Data.TRANS_DATE <= Table.DATE". Note that the inclusion of inequality relations, as well as the possibility of duplicate join keys, means that multiple Join records may be output for each Data record.
The Join2 tool does not have the same Join types as the Join tool. However, it does have a Unique table option.
Should I use Join2 or the Join tool?
-
If you need inequality relations between keys, use the Join2 tool.
-
When the Table input is small enough to load into memory, use the Join2 tool. It is much faster because it does not sort the inputs.
-
For very large Table data that will not fit in memory, use the Join tool.
-
If you need the One-to-one Join type, you must use the Join tool.
Join2 tool configuration parameters
The Join2 tool has one set of configuration parameters in addition to the standard execution options.
|
Parameter |
Description |
|---|---|
|
Unique table |
If selected, discards Table records with duplicate keys. The first record is used and the rest are ignored. |
|
Case insensitive |
If selected, ignores capitalization when comparing fields. |
|
Join fields |
List of fields on which to perform the Join, and the relations between them. Each entry is composed of:
|
|
Rename fields |
List of fields to be included in output. You can select them individually, or choose from Select all, Select none, Select non-conflicting, Rename conflicting, or Remove non-existent. All fields in the output record must have unique names. |
|
Automatically select new fields |
If selected, any upstream field that is not specified in Rename fields will be selected automatically on output. |
Configure the Join2 tool
-
Select the Join2 tool, and then go to the Configuration tab on the Properties pane.
-
Optionally, select Unique table to discard Table records with duplicate keys.
-
Optionally, select Case insensitive to ignore capitalization when comparing fields.
-
In the Data field box, type or select one or more Data input records that you want to match against the Table input records.
-
In the Table field box, type or select the one or more fields from the Table input records that you want to match against the Data input records.
-
Optionally, choose the fields you wish to output: use the check boxes to select them individually, or select Select fields to choose from:
-
Select all
-
Select none
-
Select non-conflicting
-
Select highlighted
-
De-select highlighted
-
Toggle highlighted
-
Rename conflicting
-
Remove non-existent
-
All fields in the output record must have unique names. You can also add a common prefix or suffix to all field names by using the Rename tool on one of the inputs before it enters the Join2 tool. This makes the fields easy to identify and split apart.
-
To automatically select new fields that can be added when you change the input to the Select tool, check the Automatically select new fields box. This is useful if you are creating a project for repeated use and think the data you are processing may have fields added in the future.
-
Optionally, go to the Execution tab, and then set Web service options.