

Overview
A Clustered Audience can be generated from a standard selection rule. RPI uses Redpoint Automated Machine Learning (AML) to analyze a set of data, targeted by the rule, to identify within the same a series of discrete clusters. The clusters are then used as the basis for a new audience’s outputs. The results of test execution of a newly-generated Clustered Audience are displayed for inspection within the Audience Insights Window.
Clustered Audiences are created in the standard selection rule toolbox’s Clustered Audience section:

When initially displayed, the section contains a s single option:
Generate New Audience
This button allows you to automatically generate an audience exposing outputs based on Redpoint Automated Machine Learning (AML) clusters from the current selection rule. If you select the button when the rule contains unsaved changes, a warning is shown.
If system configuration setting AutomatedMLAPIAddress has not been set, the following message is shown:
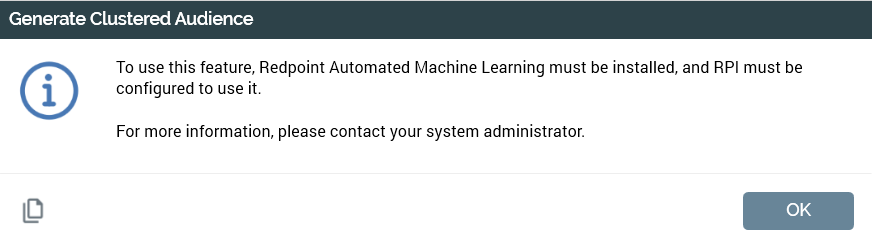
Selecting the button displays the Generate Clustered Audience overlay (covered separately). If no training sets compatible with the rule's resolution level exist, a warning message is displayed and the overlay is not shown.
After creation of a Generate Audience job, the button is unavailable, and its text is updated to "Generating Audience...". The Job status is shown, consisting of an overall "Waiting for Execution" or "Executing" status, along a more detailed description of the current activity. Job status is shown when the Generate Audience job is complete.
When the Generate Audience job is complete, the button is available again, and its text set to "Generate Another Audience". The Latest Generated Audience section is also shown (covered separately).
If audience generation fails, the following are shown below the button:
-
"The last job to generate an audience failed"
-
Top-level error message
-
Copy Error Log to Clipboard button
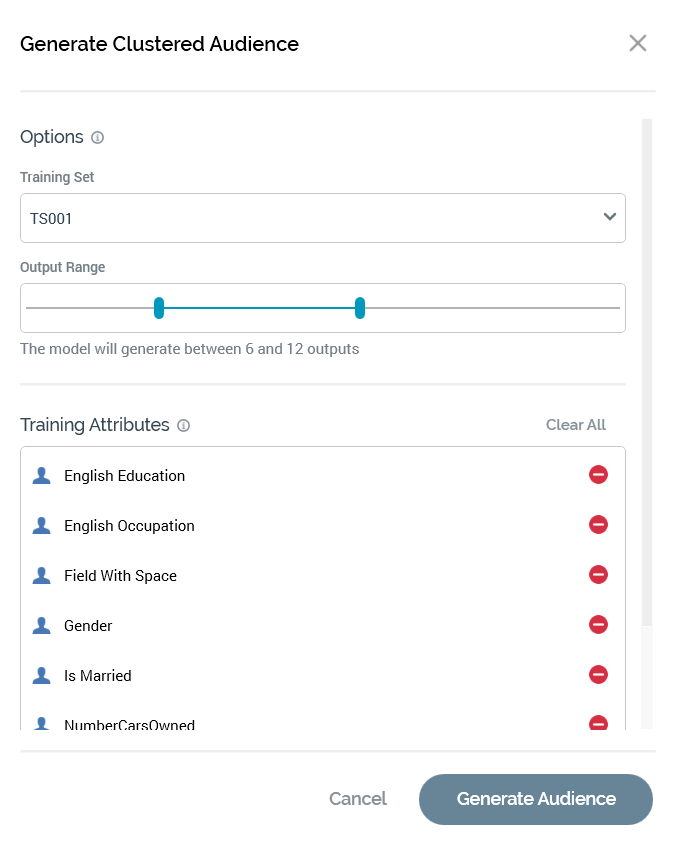
Generate Clustered Audience
The Generate Clustered Audience overlay contains the following:
-
Warning: if an audience generated from the current interaction has been used in a Test or Production interaction workflow, and its training set's Model project and audience files property is set to Re-use existing files each time this training set is used, a warning is shown at the top of the overlay.
-
Options section: contains:
-
Training Set: this dropdown is only shown if more than one training set can be sourced from audience definition's compatible with current rule's resolution level. The property lists training sets as described. Note that if only one such training set exists, the property is not shown and the training set in question is used automatically.
-
Output Range: a slider control can be used to define the audience's minimum and maximum number of outputs. The default minimum value is 6, and the default maximum value is 12. A range of 2 to 20 is supported, and a range of at least 3 values must be provided.
-
-
Training Attributes section: this section is used to define the attributes used to source training data to build the cluster model. The property consists of a toolbar and list.
-
Toolbar: exposing a single option:
-
Clear All: this button is displayed when at least one training attribute is present in the list. Selecting it removes all attributes from the list. An "Are You Sure?" dialog is not shown.
-
-
List: the initial list of attributes is provided by the chosen (or default) training set. Attributes are presented alphabetically. An inline Remove Attribute button is provided at each. When the list is empty, a message displays reading “Please add at least one Attribute by dropping Attributes or Export Templates here”. You can add attributes to the list using drag and drop. An attribute cannot be added if already present in the list. You cannot add Exists in Table or Parameter attributes. You can also add the attributes from an export template using drag and drop. Dragging in a NoSQL export template has no effect. Note that changing the Training Set loses any changes made manually to the list of attributes.
-
Footer
Contains:
-
Cancel: selecting this button removes the overlay from display. Selecting off the overlay has the same effect.
-
Generate Audience: selecting this button creates a "Generate Audience from [Rule Name]" job and closes the overlay. The job's description is "AML Model Builder". The My Jobs dialog is not displayed.
Note that you can refresh a selection rule’s count while a clustered audience is being generated at the same.
On the job's completion, a View Results button is available at the job when displayed in the My Jobs dialog. Selecting the button displays the Audience Insights Window, in which are displayed the newly-generated cluster audience's test execution details.
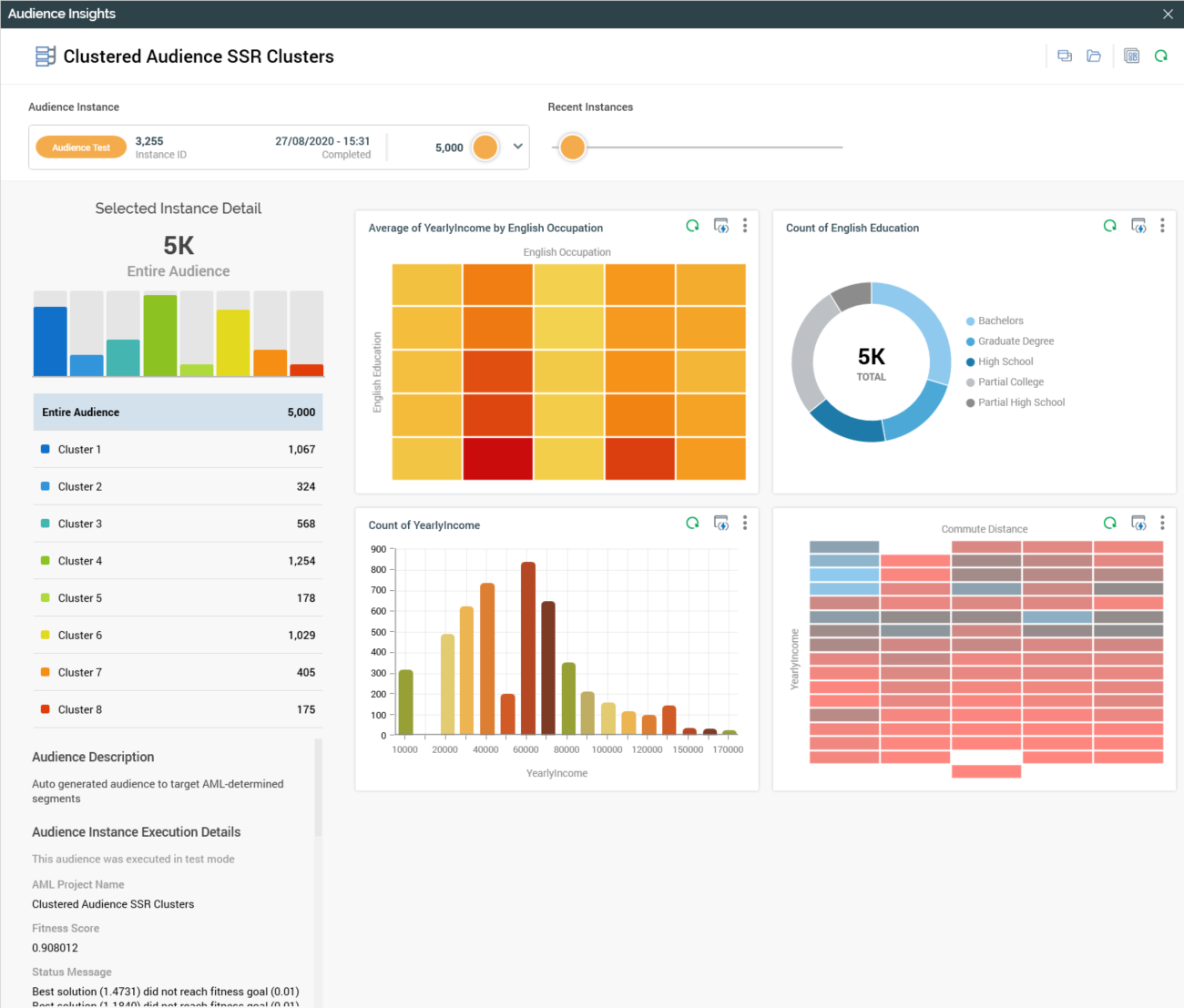
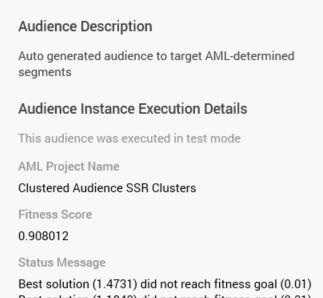
Results are capped in accordance with the training set's Initial Audience Test Cap property. Additional properties provided by AML are shown below the Audience Instance Execution Details section:
Latest Generated Audience
The Latest Generated Audience section is displayed when a clustered audience has been generated from a selection rule. It contains the following:
-
View Audience Insights: selecting this button displays the audience's details in the Insights Window. Please see above for more information.
-
Open Audience: selecting this button open the clustered audience in the Audience Designer. A clustered audience contains the following:
-
Name: set to "[Selection Rule name] Clusters".
-
Description: set to "Auto-generated audience to target AML-determined segments".
-
Filter: named as per the selection rule, and configured with the standard selection rule from which generated.
-
Model Scoring block: named as per the audience, as is the model project with which configured. Its outputs are automatically generated in accordance with the clusters identified by AML. Each output is named "Cluster [n]", where [n] is an incrementing integer. Each output is associated with a band with the same name.
-
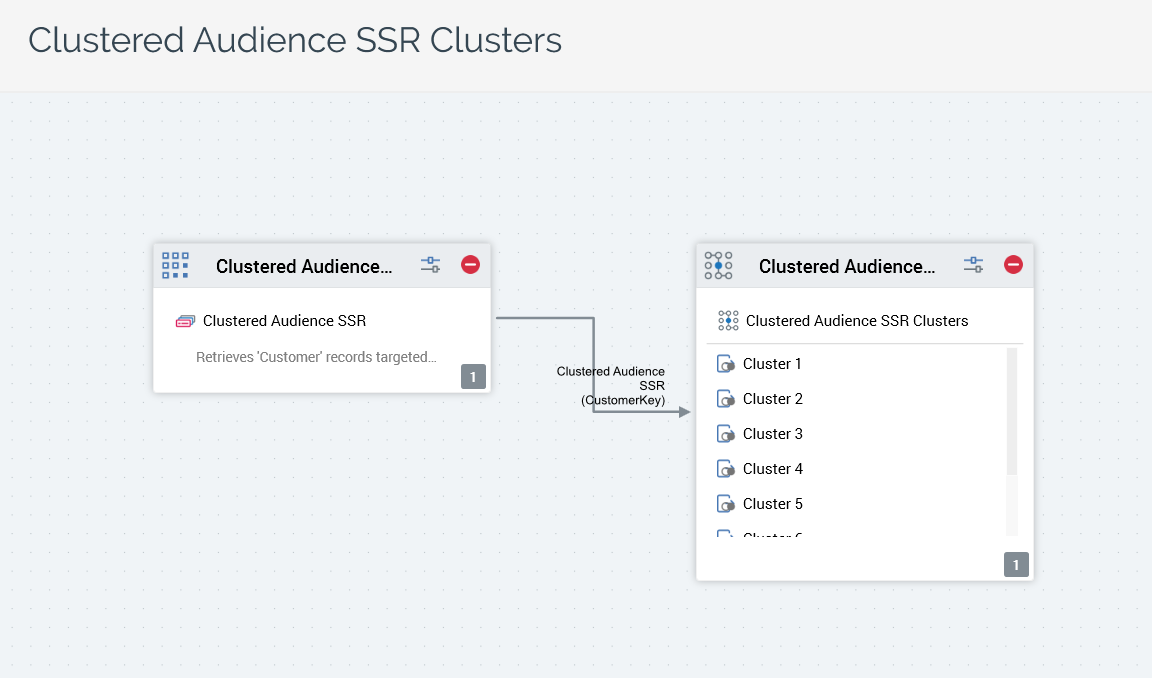
The model project generated by AML contains the following:
-
Model name: set to "[Selection Rule name] Clusters". Note that an incrementing integer can be appended to ensure uniqueness.
-
Type: Clustering.
-
Output field: "Cluster".
-
Attributes: as passed from the selection rule.
Model Score bands are generated automatically based on the clusters identified by AML. Bands are named as per audience outputs (i.e. "Cluster [n]"). Each band has a single assigned value, starting at 0 and incrementing upwards.
Audience and Model Project files are saved in a folder identified by the training set's Model project and audience folder property. If the training set's Re-use model project and audience files property is set to "Re-use existing files each time this training set is used", the audience and model project files are overwritten each time a clustered audience is generated. If set to "Create new files each time this training set is used", new audience and model project files are created each time a clustered audience is generated. "_[n]" appended to filenames to ensure uniqueness (where "[n]" is an incrementing integer).