

Overview
A cluster is a collection of Execution Servers, all connected to the same Site Server, one of which is designated as the Master. The servers that are not the Master are Workers. The Master server can also be listed as a Worker (and normally is). Computers in a cluster cooperate in different ways to improve throughput, management, and reliability of Data Management processing.
You can use clusters for queuing and load balancing:
-
Queuing: servers will prevent more than a specified number of projects from running simultaneously to avoid overload. Excess projects wait for a turn in the job queue.
-
Load balancing: by default, projects run from the command-line will load balance, meaning that a project can run on any of the workers in the cluster.
Design a cluster
The computers in a cluster need not be identical, and workers can be defined with different load limits. A typical configuration might consist of:
-
Master: a reliable server with SAN storage.
-
"Fat" Workers: multiple servers, each of which has eight direct-attached storage disks or SSD, 16 CPU cores, 64GB RAM, and a 1GB network connection.
-
"Thin" Workers: multiple servers, each of which has four direct-attached storage disk, 4 CPU cores, 16GB RAM, and a 1GB network connection.
The Master should also be more reliable than the Workers because it coordinates all of the effort, whereas the workers may use workstation-class components and non-redundant temporary storage.
Each Worker in the cluster must have its own local temp space storage. Failing to provide local temp space storage will eliminate the benefits of clustering.
Do not use network shares for temp space.
Use SAN volumes for worker temp space only if each worker has a SAN partition with completely exclusive access to its volumes' disk spindles.
Master-as-Worker
Because the Master is likely to be a fast computer, it should also be in the worker list.
Default cluster-of-one
Any Execution Server that is not listed in a cluster is considered a cluster of one. This cluster contains the computer as both master and worker, and has a default maximum load of eight. The default cluster-of-one is useful for queuing and load-limiting and provides backwards-compatible behavior.
Requirements for load balancing
When multiple workers are defined in a cluster, project runs can be load balanced. This is the default behavior of the command-line application. However, the Data Management servers, your projects, and your network must be properly designed for load-balanced projects to run correctly and identically independent of the worker. In particular, you should observe the following rules.
File paths must be uniform and accessible
All file paths referenced by load-balanced projects must be accessible and must reference the same data on all workers in the cluster. For example, if a project refers to a file in F:\data (Windows) or /data (Linux), that folder must be accessible and must refer to the same data on all workers. You can meet this requirement in two ways:
-
Define resource maps in the Data Management repository under
/Settings/Machines/for all data that you want to access on the cluster. This lets you define the same resource map to refer to local or network storage as needed. For example, you could define the resource mapMyDatato refer toF:/MyDataon the computer owning the filesystem, but//Server1/MyDataeverywhere else. Use those resource maps in your projects instead of direct file paths. -
Use the operating system to drive-map (on Windows) or mount (on Linux) network shares so that they appear the same on all workers.
Furthermore, the login used by the Data Management services on each worker must have operating system permission to access the files.
Databases must be accessible
Databases tend to be less problematic than file shares. However, you may need to configure permissions and/or database name indirections depending on the kind of RDBMS, so that each worker can access the referenced databases using the same names and configuration settings.
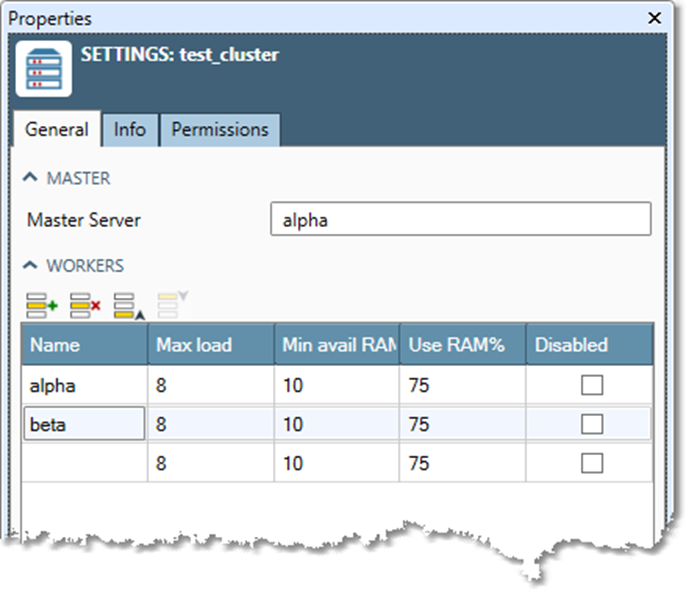
Configure a cluster
To configure a new cluster:
-
In the repository, open the Settings folder.
-
Right-click Clusters, and select New Cluster.
-
Enter a name for the new cluster when prompted.
-
Select the new cluster in the repository tree, and view the Properties pane.
-
Enter the name of the Master Server.
-
For each Worker server, enter:
-
Name: the name of the worker.
-
Max load: the maximum number of projects that can run at one time on the worker.
-
Min avail RAM %: the minimum percentage of system memory that must be available for projects to run on the worker.
-
Use RAM%: the maximum percentage of system memory that can used by projects run on the worker.
-
If the master server is also a worker (if it will run projects along with the other workers), you should also define it as a worker.
The maximum number of projects and minimum available memory will depend on the amount of memory allocated to each project compared to the size of the computer (see Tuning), and the load response of the server on typical projects. For example, you may find that while your servers can run eight projects at once, they actually complete faster in aggregate if you restrict the cluster to running three projects at a time and allocating more memory to each project, thus reducing storage system contention. See also the guidelines suggested in Designing a cluster and Requirements for load balancing for additional settings relevant to clustering.
Clusters and interactive project runs
When you log into Data Management with the client, you still specify an Execution Server, which can be the Master or any of the Workers. Selecting the right-facing green triangle in the client runs the project on the connected server, without load-balancing. However, the project run may have to wait for resources to become available on that server. If resources are unavailable, you will see this message.
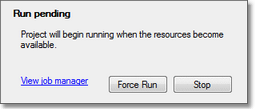
Take one of the following actions:
-
Wait: this is the recommended approach if the project cannot be load-balanced due to server-specific resources.
-
Force the project to run anyway: this is only possible if you have Administrator privileges. This is not recommended unless you are a very experienced user and you know that it will not overload the server.
-
Cancel the run and queue it for load balancing: this is recommended if the project is suitable for load balancing (all file paths use resource maps or network shares).
-
Cancel the run and log into a different server to run it: this is not recommended, as it is tedious. It is better to make the project load-balancing compliant and queue it for load balancing.