

Overview
Before using the Window Compare tool, consider a higher-level component like one of Data Management's pre-built matching objects. The AO Matching objects contain many pre-tuned, high-quality matching solutions that perform very well for a variety of needs. Use the Window Compare tool when you need finer-grained control than the pre-built macros offer.
Window Compare is a specialized tool used for merge/purge, householding, data integration, and other fuzzy-matching processes. Use the Window Compare tool to determine if two similar records are similar enough that they should be considered the same record in some sense. In the classic merge/purge application for mailing lists, the definition of "sameness" hinges on the type of entity the mailing wants to reach: occupant, family, or individual. In data-integration applications, the entities might be individuals, business franchises, replacement parts or any other named entity.
The input to Window Compare is usually the output of a Sort tool, which orders records such that likely duplicates are close enough to compare. Window Compare is also often connected as an input to the Pair To Group tool, which transforms the results of record matching into match groups, which can then be used for householding or deduplication.
The Window Compare tool scans the input records, sliding a virtual window across the input and comparing all records within the window using rules that you specify. When two records match, a pair of identifying values (one for each record) is written to the output. The size limits of the window together with an optional segmentation determine which records are to be compared.
To configure the Window Compare tool, you construct a set of matching rules that determine which records are similar enough to be treated as the same entity. These matching rules specify:
-
Records to compare (window size and/or segmentation).
-
Algorithms used to compare the data in the records.
-
Quality thresholds that must be met.
-
Reference data (such as nickname tables) to handle special cases.
Selecting records to compare
There are always two parts to record comparison: (1) choosing which records should be compared to each other (sometimes called "blocking"), and (2) comparing the fields in the records using various comparison techniques. Let's first define some of the terms used in talking about the Window Compare tool.
In the first step, selecting records to compare, you choose one of three basic strategies.
A match segment is a synthetic data key used to determine which records should be compared to each other. In its simplest application, every record with the same segment value is compared to every other record with that value, and no others. A segment is typically built using pieces of other fields. The following are typical ways to construct a segment for name/address matching:
-
ZIP code: this is a "loose" segment, resulting in many record comparisons. Should be used only for very dirty data and/or small record sets.
-
ZIP + (first two digits of address): this is a "medium" segment and tends to produce good results.
-
ZIP + (first two digits of address) + (first letter of street name): this is a "tight" segment that is good for very large data sets.
A window size, as we use term here, is a boundary on the "distance" of records to compare, based on their position in the sorted record data. For example, a window size of eight implies that every pair of records that sorts within eight positions of each other will be compared.
For any of the strategies discussed below, you must sort the records upstream of the Window Compare tool, such that likely matches are close together in the sort order: If you use a segment, the record must be sorted on that segment value, and perhaps more low-priority keys.
Given those definitions, we can talk about the three "blocking" strategies for selecting records to compare:
-
No Segmentation: uses only a window size. Choose this strategy when your data is too dirty to rely on segment information, or when you don't have any clear segment boundaries (such as when you are comparing solely on business name). Window sizes of 8 to 20 are typical. Use a larger window size for very dirty data. The number of comparisons is proportional to the window size, so your projects will run slower as the window size is increased.
-
Flexible Segmentation: uses both a window size and a segment value. Choose this strategy when you have a clear segment value, but its possible due to noise in the data that you need to compare other records that are only "close" to the segment. It also helps you control the number of comparisons in the event that you have a degenerate segment computation where thousands of records are accidentally assigned the same segment due to bad data. In addition to the segmentation key field, you will also specify minimum and maximum window sizes. Typical values are 8 for the minimum window size and 200 for the maximum.
-
Strict Segmentation: uses only the segment value. Choose this strategy when you have a field or computed value (such as ZIP Code plus first three digits of address) that determines which records to compare—all records with the same segmentation value are candidates for comparison, and no others should be compared. This is typically the best for data that has been pre-cleaned and parsed. Be careful to exclude records with "empty" segment values from the comparison, or your project may experience runaway computational times.
Comparison Algorithms
The Window Compare tool offers four different comparison algorithms:
-
Positional: compares each character position within the two records. Each mismatched character is counted as one error.
-
Edit distance: compares the fields of the two records using an algorithm that counts how many "mistakes" were made to transform one field value into the other.
-
Edit distance (QWERTY): similar to Edit distance, except that characters adjacent to each other on the QWERTY keyboard count as one-half of an error.
-
Word-by-word: compares the fields of two records by splitting the text of each field into words) and then comparing the words one at a time. This method is often used for business-name comparison where word order is not as important.
You can define complex window comparisons involving averages of several field comparisons of different kinds and weights. The Window Compare tool assigns a score to each pair of compared records, calculating the score by combining the scores and weights of the individual field comparisons. Two records are considered a match when the record comparison score exceeds the specified threshold.
Reference Data
The Window Compare tool lets you import reference data tables from any source, to handle nicknames, aliases, synonyms, and trivial words.
Window Compare and other tools
You usually connect the Window Compare tool downstream from a Sort tool. Configure the Sort tool so that it places likely duplicates close to each other in the resulting sorted table. Because the Window Compare can only compare records that fall within the same window, choosing a good sort order is important. Typically, if you are using a segment, the segment field will be the first key in the sort. You may find that multiple sort/compare passes are necessary to achieve the results you want.
Window Compare tool configuration parameters
The Window Compare tool has two sets of configuration parameters in addition to the standard execution options.
Configuration
|
Parameter |
Description |
|---|---|
|
Key field to output |
Input field that uniquely identifies each record. |
|
Segmentation type |
Determines how the segment, if one is defined interacts with window size. This is optional and defaults to None. |
|
Segment |
If Segmentation type is Strict or Flexible, the field defining the segmentation of the comparison. |
|
Window size
|
The size of the "window" used when comparing records. This varies by Segmentation type. |
|
Scoring method |
Specifies how the match scores of the individual field comparisons are combined to form the record match score. This is optional and defaults to Weighted Average. |
|
Match threshold |
The score threshold above which two records are considered a match. This is optional and defaults to 90. |
|
Output match score |
If selected, outputs the match score between the two records to specified Output match score field. |
|
Output match score field |
Field to receive Output match score. |
|
Reject match if field is equal |
If selected, assigns a match score of 0 to any two records containing the same values in the specified Reject field. |
|
Reject field |
Field used to reject matches. |
|
Optimize for pair to group tool |
If selected, suppresses redundant pairs generated for large groups. |
|
Compute output score without field thresholds |
If selected, computes match score ignoring field-match all-or-nothing thresholds. |
Comparisons
|
Parameter |
Description |
|---|---|
|
Field |
The field to compare. |
|
Comparison |
The kind of comparison to perform. This is optional and defaults to Positional. |
|
Field2 |
If specified, second field to compare with the first one. Four different comparisons will be made: Field/Field, Field/Field2, Field2/Field, Field2/Field2. The highest score of any combination is output as the result. |
|
Cross compare |
If Field2 is specified, you can select first/middle name logic to cross-match only if one of the Field2 values is blank. |
|
Weight |
The relative weight given to this comparison when computing the total match score. This is optional and defaults to 100. |
|
Use threshold |
If selected, use the threshold "all or nothing" score for the comparison. |
|
Threshold |
If specified, all field match scores greater than or equal to this threshold will be changed to 100, and all other scores will be changed to 0. |
|
Must match |
If selected, the field must match in order for the record to be classified as a match. |
|
Compare aliases on |
If specified, compare the Entire field or a Word or field to a data source containing common abbreviations, nicknames, or aliases. Alias input # identifies the alias table input by its connection position. |
|
Skip trivial words |
If Comparison kind is Word-by-word, optionally select Skip trivial words to specify words that should be ignored in the comparison. |
|
Trivial words # |
If Skip trivial words is selected, specify which A input is the trivial words table. |
|
Other parameters |
Configure the Window Compare tool
Before configuring the Window Compare tool you should:
-
Decide whether to use a segmentation field. The segmentation field defines a flexible window size within which records are compared. The data must be sorted in advance using this field as the primary sort key. Choose your segmentation field carefully to avoid too many comparisons. A good average segment size is about 10. A common segmentation uses a computed field that combines the 5-digit ZIP code with the first three digits of the address number or the soundex of the last name.
-
Decide whether to score each field comparison independently (field scoring) or score record comparisons as a whole (record scoring).
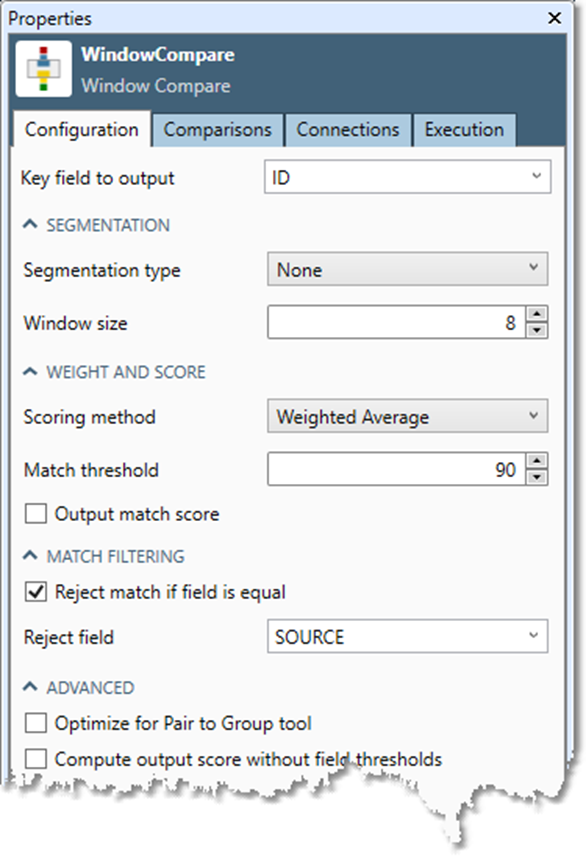
To configure the Window Compare tool:
-
Select the Window Compare tool.
-
Go to the Configuration tab on the Properties pane.
-
Select a unique key field from the Key field to output list. This field must uniquely identify each record.
If you are householding multiple sources, this field must be unique for each record across all source tables. If your sources don't have a unique identifier, you can add one using a combination of the Generate Sequence tool and a Select tool. See the householding and merge/purge topics for more details.
-
Optionally, specify a Segmentation type:
-
Strict segmentation: requires a segmentation match, preventing records from matching outside their own segment. Select this option when an exact match on the segment value is a defining part of the match criteria.
-
Flexible segmentation: does not require a match on the segmentation field and allows window size to vary dynamically. This lets you balance performance and quality, and makes matching less dependent on the size and nature of the data.
-
-
If you specified a Segmentation type, select the segmentation field from the Segment list.
-
Specify a Window size. If you do not specify a segmentation field, choose a Window size that balances performance with match quality. Larger window sizes require more system resources. Specify a slightly larger window for more data or for data containing many duplicates.
-
100,000 records with few duplicates can use a Window size of 7.
-
10,000,000 records with few duplicates can use a Window size of 12.
-
10,000,000 records with many duplicates can use a Window size of 16.
-
-
If you specify Flexible segmentation, Window size changes to Min window size, and the Max window size setting is available. The window size will vary dynamically between Min window size and Max window size. Typical settings when using segmentation are a Min window size of 6 and a Max window size of 100. If you do not specify a Max window size, you will effectively get an unlimited window, expanding as necessary to handle the segment. See also Segmentation size.
-
If you specify Strict segmentation, the Min window size box is hidden and has an effective value of 1; set the Max window size to 100 or more.
These figures are only guidelines. The best way to judge window size is to do a sample run of your merge/purge or householding project, examine the results (number of matches), and then increase the window size and compare the results of the two runs. If you find that you need a very large window, you will often do better by adding more sort/compare passes instead of a larger window size.
-
Optionally, select Output match score and specify an Output match score field. This outputs the match score between compared records as a percentage between 1-100.
-
Optionally, check the Reject match if field is equal check box and specify a Reject field that uniquely identifies the source table of each record.
If you are householding several tables, you may not want matches to be found within the same table—you may only want cross-table matches. Select the Reject match if field is equal check box, and specify a field that uniquely identifies the source table of each record. If your source tables don't have a unique identifier, you can add one to each table using the Calculate tool to assign a constant value to a new "Source ID" field. See Householding multiple tables using "fuzzy-matching" for an example of using a "Source ID" field to avoid intra-table matches.
-
If you will use a Pair to Group tool downstream of the Window Compare tool, select Optimize for pair-to-group to improve matching performance.
-
If you are using field scoring and have a threshold on each field comparison, the output score is usually 100 because all fields meet their threshold. If you want to know what the record score would have been with no field thresholds defined, select Compute output record score without field thresholds.
-
Select the Comparisons tab and define one or more field comparisons.
-
Optionally, go to the Connection Order tab and adjust the order of alias connections. Since multiple upstream data sources can be connected to the "A" input of a single Window Compare tool, you may need to identify the alias table and trivial words table inputs by their connection position. For example, an aliases CSV data source might be connected as position 1, and a trivial words data source as position 2.
-
Optionally, go to the Execution tab, and then set Web service options.
Segmentation size
If you are using segmentation in your matching and do not set a maximum window size, the size of one or more of the segments may become quite large. Because the number of comparisons performed in a segment is proportional to the segment size squared, very large segments can slow the execution time of your project. For example:
-
A segment size of 1000 requires 1,000,000 comparisons. Matching starts to slow down.
-
A segment size of 8000 requires 64,000,000 comparisons. Matching times can be long.
-
A segment size of 32000 requires 1,024,000,000 comparisons. Matching may take many days.
Data Management generates a warning for the first segment value for which the segment size exceeds 1000, 2000, 4000, and so on. It does not issue a warning for every segment that exceeds each threshold, only the first one encountered.
Add a field comparison
-
Select the Window Compare tool.
-
Go to the Comparisons tab.
-
Select a row in the Comparisons grid.
-
From the Field list, select the field to compare.
-
From the Comparison list, select a field comparison method.
-
Positional: compares each character position within the two records. Each mismatched character is counted as one error.
-
Edit distance: compares the fields of the two records using an algorithm that counts how many "mistakes" were made to transform one field value into the other. Transposition mistakes count as 1/2 error. Substitution mistakes count as one error. Insertion/deletion mistakes count as one error, except deletion of a doubled character is 1/2 error.
-
Edit distance (QWERTY): similar to Edit distance, except that substitutions are counted as 1/2 error for keys adjacent to each other on the QWERTY keyboard, and as one error for non-adjacent keys.
-
Word-by-word: compares the fields of two records by splitting the text of each field into words (punctuation and spaces are dropped) and then comparing the words one at a time. This method is often used for business-name comparison where word order is not as important. Choosing Word-by-word comparison enables many options in the Options section.
-
Numeric: compares numeric (Integer, Float, or Decimal) fields. Produces a score by calculating the ratio of the difference in the values to the average of the values.
-
-
Optionally, you can specify Field 2 to cross-compare a second field with the first one. For example, your data might contain two company-name columns, and you want to consider both columns in the match. Specifying one company name field as Field and the second company name field as Field 2 will compare all combinations of the two fields and choose the best score.
|
Field |
Field 2 |
|---|---|
|
COMPANY |
COMPANY2 |
|
ABC CORPORATION |
AMALGAMATED INDUSTRIES |
|
C/O JANE SMITH |
ABC CORP |
By specifying both COMPANY and COMPANY2 in the match, you find the match between ABC CORPORATION and ABC CORP.
-
If you specify Field 2, you can optionally choose to Cross compare using First/middle name logic.
-
In the Weight box, set the weight of the field. This is only applied when the Weighted average scoring method is select the Configuration tab.
-
Optionally, check the Use threshold box and adjust the Threshold value. This changes the field score to zero if it is below the specified threshold, and 100 if it is above the threshold. This effectively requires "perfect" matches on the specified field. Use this if you are using field scoring.
-
Check Must match if the field must match in order for the record to be classified as a match. This is useful for matching within a known group, as when matching individuals of known families. It is also useful when you know you have "deal breaker" columns, such as ZIP Code.
-
Optionally, you can Compare aliases on to match common abbreviations, nicknames, or aliases. Specify whether to compare the Entire field or a Word or field. Since multiple upstream data sources can be connected to a single Window Compare tool, you must identify the alias table input by its connection position. For example, an aliases CSV data source might be connected as position 1, and a trivial words data source as position 2. See Specifying an alias table.
-
If you specified Comparison kind as Word-by-word, you can optionally select Skip trivial words to specify words that should be ignored in the comparison. Specify which A input is the Trivial words table. See Specifying a trivial words table.
-
Optionally, configure advanced options. We recommend that you use these options only after gaining some experience with Data Management's matching techniques.
-
Repeat to add more comparisons.
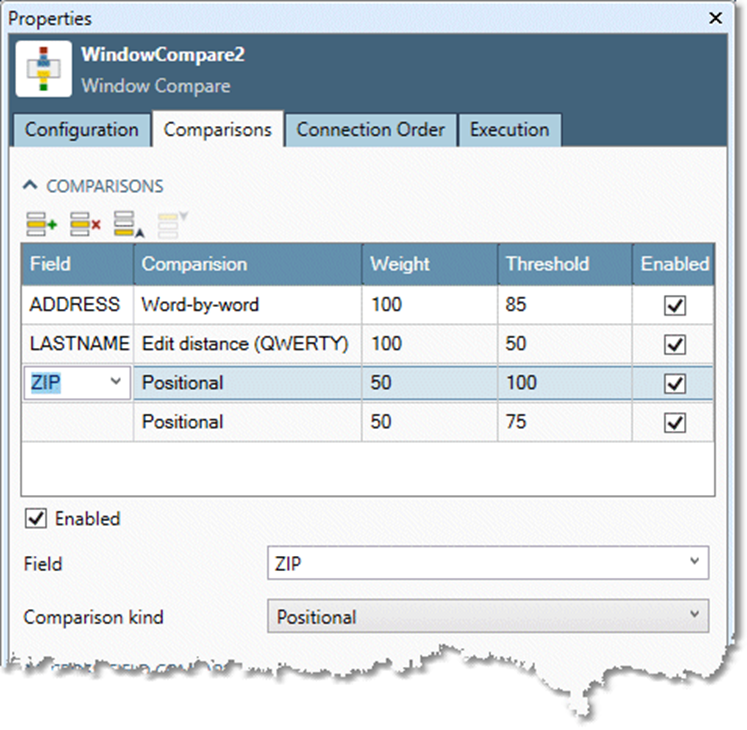
Add a field comparison: Advanced options
Various advanced options are available, depending on the comparison kind you've selected. We recommend that you use these options only after gaining some experience with Data Management's matching techniques.
To configure advanced field comparison options:
-
Select the Window Compare tool.
-
Go to the Comparisons tab and select a field in the Comparisons grid.
-
Blank match controls how empty fields are compared. Sometimes you want to treat missing information as "unknown" and ignore it, but other times you want to treat it as significant and require a match. Note that for variable-length text fields, spaces are trimmed before comparison so spaces are also considered blank.
-
None: blank values will not match anything, not even other blanks. Use this setting if blank information is significant and should not be interpreted as "missing."
-
Blanks to blanks: matches blank values to blank values.
-
Blanks to non-blanks: matches blank values to non-blank values. Does not match blanks to blanks. Rarely used except in advanced matching techniques involving computed codes that indicate type and availability of data columns.
-
All: matches blank values to blank and non-blank values. Use this setting if you are comparing gender, unit number, or other "likely missing" information, and you are using blank to indicate "unknown." For example you don't want these similar names to match.
-
|
Name |
Gender |
|---|---|
|
ALEXANDER |
M |
|
ALEXANDRA |
F |
But you do want these similar names to match.
|
Name |
Gender |
|---|---|
|
ALEXANDER |
M |
|
ALEXANDR |
|
Match numeric lets you specify a secondary match threshold for the digits contained in the match values. A second match is performed on the digits of both values using an edit distance algorithm. The numeric score is computed by extracting all the digits, and applying the following rules:
-
If both digit sets are blank, it is a match.
-
If only one digit set is blank, it is a non-match.
-
If both digit sets are non-blank, they are compared using Edit Distance Qwerty rules.
If this match fails to meet the threshold, the entire match fails. Use this if your field contains both digits and non-digits, but the digits are more critical to the match.
Examples of the numeric scores and expected numeric matches.
|
Numeric score |
Expected numeric matches |
|---|---|
|
SMITHFIELD RD
|
One digit set is blank and the other is not.
|
|
SMITHFIELD RD
|
Both digit sets are blank.
|
|
630 SMITHFIELD RD
|
Transposition counts as half-error.
|
|
530 SMITHFIELD RD
|
Substitution of 5 with 6 is Qwerty-adjacent, counts as half-error.
|
|
530 SMITHFIELD RD
|
Substitution of 5 with 9 is a whole error.
|
The match/non-match status is for the numeric part of the match values only.
Match initials matches a single letter to words that begin with that letter, and assigns the specified Score as the result score.
Examples:
|
Match initials |
Score |
|---|---|
|
J
|
This pair matches when the Match initials option is selected. |
|
I B M
G E FINANCE
|
These pairs match only when the Match initials option is selected and you've specified a word-by-word comparison type. |
Match acronyms matches small words to a sequence of words that begin with the letters of the first word, and assigns the specified Score.
Examples:
|
Match acronyms |
Score |
|---|---|
|
IBM
GE FINANCE
|
These pairs match only when the Match acronyms option is selected and you've specified a word-by-word comparison type. |
Match abbreviations (only available if you've specified a word-by-word comparison type) matches words that are similar using a proprietary abbreviation-matching technique that models typical abbreviations. You can also specify an Adjustment that controls how highly abbreviations are scored. Higher values of the adjustment produce higher scores for abbreviation matches. Match abbreviations is useful for matching sets like the following:
DEPT OF REVENUE
DEPARTMENT OF REV
INTERNATIONAL MONETARY FUND
INTL MONETARY FUND
INTERNATL MONTRY FND
Match abbreviations complements the Alias table input option, enabling you to pick up both algorithmic and special-case abbreviations.
-
Quality threshold (only available if you've specified a word-by-word comparison type.) specifies the minimum quality of a word match. Words matching at a lower quality are considered non-matches. You should rarely need to change this from its default value.
-
Subset match adjustment. (only available if you've specified a word-by-word comparison type) controls the score assigned to word matches when one field value contains a subset of the words in the other field value. Higher numbers for this setting will cause word-subset matches to result in higher scores. You should rarely need to change this from its default value.
-
Sensitivity (only available if you've specified a numeric comparison type) differentiates values that are close together.
Examples
With Sensitivity set to 1 (default value):
|
Value1 |
Value2 |
Field Score |
|---|---|---|
|
100 |
101 |
99 |
|
95 |
105 |
90 |
|
25 |
75 |
50 |
With Sensitivity set to 10:
|
Value1 |
Value2 |
Field Score |
|---|---|---|
|
100 |
101 |
90 |
|
95 |
105 |
0 |
|
1000 |
1001 |
99 |
|
1.000 |
1.010 |
90 |
Zeros as blanks (only available if you've specified a numeric comparison type) specifies that values of zero are treated as blanks for the purposes of the Blank match setting (see Step 2).
Specify a trivial words table
When matching many kinds of text, especially business names, you may find that the presence of "trivial" words interferes with the match. Also known as "noise" words, these may be participles such as "A", "AN", "THE", or optional words like "DEPT", "INC", "CORP", or "LLC". Specifying an appropriate list of trivial words lets you match strings like "THE ABC CORP" to "ABC". In the Window Compare tool, if you specify a Comparison kind of Word-by-word, you can select Skip trivial words to specify words that should be ignored in the comparison.
To specify a trivial words table:
-
Create a single column spreadsheet using Microsoft Excel or a similar application.
-
List all the values you want to identify as trivial words, with one field per row.
-
Use the Save As command to save the file in CSV (Comma Separated Value) format.
Alternatively, you can use a text editor to create the CSV file directly.
-
Connect the CSV data source to the "A" input of the Window Compare tool.
-
On the Comparisons tab of the Window Compare tool, select Skip trivial words and specify the number of the input, if necessary.
Since multiple upstream data sources can be connected to the "A" input of a single Window Compare tool, you must identify the trivial words table input by its connection position. For example, an aliases CSV data source might be connected as position 1, and a trivial words data source as position 2.
Specify an alias table
When matching individual names or business names, there are many cases where matching on an alternate word is desirable. Some examples: matching nicknames (JOHN to JOHNNY), abbreviations (ACCTING to ACCOUNTING), and known aliases (AMALGAMATED INDUSTRIES a subsidiary of CONSOLIDATED HOLDINGS).
To specify an alias table:
-
Create a two-column spreadsheet using Microsoft Excel or a similar application.
-
In the first column, list alias values. In the second column, list the alias equivalent values.
-
Use the Save As command to save the file in CSV (Comma Separated Value) format.
-
Alternatively, you can use a text editor to create the CSV file directly.
-
-
Connect the CSV data source to the "A" input of the Window Compare tool.
-
On the Comparisons tab of the Window Compare tool, select Compare aliases:
-
Entire field matches only whole-field aliases (for example, AMALGAMATED INDUSTRIES to CONSOLIDATED HOLDINGS).
-
Word or field matches both whole-field or single-word aliases (for example, ACCOUNTING DEPARTMENT to ACCTING DEPT).
-
Specify the Alias table input.
-
-
Since multiple upstream data sources can be connected to the "A" input of a single Window Compare tool, you must identify the alias table input by its connection position. For example, an aliases CSV data source might be connected as position 1, and a trivial words data source as position 2.