Split block
Overview
A split is used to split an audience into a series of outputs.
Specific metadata values may then be applied to each output. A given split output may also serve as an input to a subsequent child block.
Split outputs can be filtered by association with a selection rule and can be capped at a specific percentage or volume.
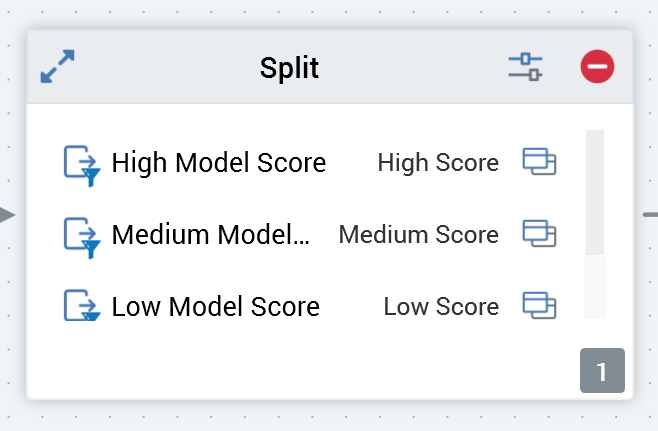
When displayed in the workspace, a split displays a list of its outputs, along with the configured selection rule and capping value for each (if assigned).
Adding a split to an Audience
You can add a new split to an audience by dragging a split from the Audience Blocks section within the toolbox. Doing so creates a new, blank split within the workspace.
By default, the new split is named “Split”. If a split named “Split” already exists within the current audience, the newly-created split is named “Split 2” (note that, if required, the numerical value can be incremented accordingly).
The new split is selected automatically.
Following the addition of a split block, an asterisk is appended to the audience’s name displayed within the current tab, indicating that unsaved changes now exist.
Configuring a split in the workspace
A split's outputs are listed within its visual representation within the workspace, and you can add outputs by dropping selection rules directly onto the split's outputs list. When you drag one or more selection rules from the toolbox and hover over a split's output list a dashed highlight is shown.
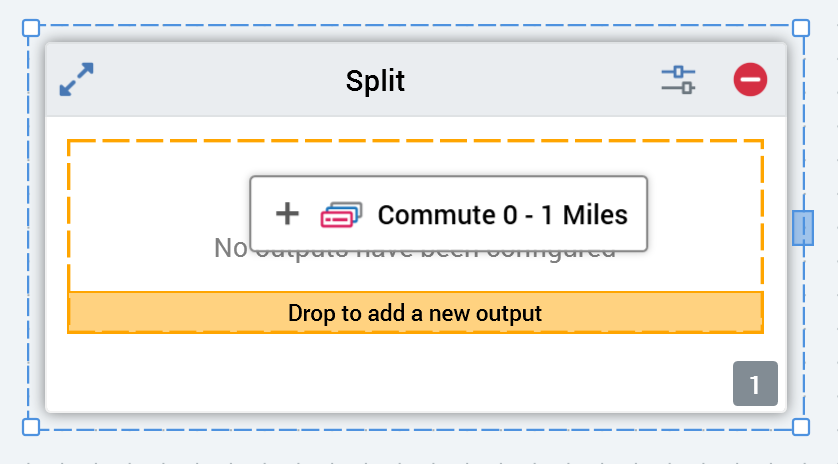
When you drop the selection rule(s), new outputs are created. The default names of the outputs correspond to the names of the dropped selection rules.
The link between the split and selection rule is dynamic—that is, the block is always linked to the most up-to-date version of the selection rule.
Any splits that are configured with selection rules are identifiable by the presence of a rule icon at each split displayed within the block.
Each split configured with a rule listed at a split block is accompanied by an inline Open Latest Version button. Selecting the button opens the rule in the Rule Designer.
Configuring a split using the Audience Block Builder
General tab
An additional property is displayed within the split block Audience Block Builder’s General tab:
Deduplicate after filtering: this checkbox is unchecked by default. At split block execution, if the property is unchecked, deduplication is performed at the block prior to application of its output filters. If checked, deduplication is performed afterwards.
Output Options tab
The following split block properties are managed in the Audience Block Builder’s Output Options tab:
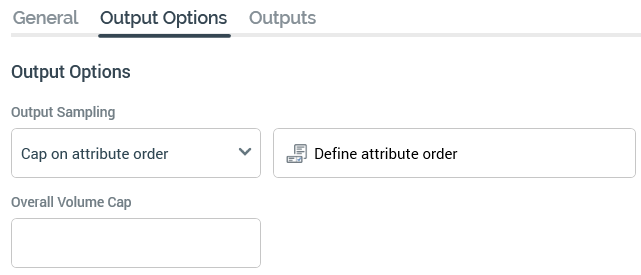
Output sampling: allows you to define how capping will be applied across the split's outputs. Output sampling is selected from a drop-down list, values for which are:
Use random capping: the default value. Records are capped randomly—as an example, say Output sampling is set to Use random capping, and an output is defined as being capped at 40,000 records. The 40,000 records will be selected randomly when an audience instance is run in an interaction.
Cap on attribute order: if this value is selected, the Define attribute order button is displayed to the right of this property. Records are chosen on the basis of their values for the attributes defined in the Define Sampling Order Attributes dialog (see Define attribute order, below, for more details).
Nthing on attribute order: if this value is selected, the Define attribute order button is displayed to the right of this property. 1 in every n of the records available to the split is selected per output, based on the order defined in the Define Sampling Order Attributes dialog.
If the exact number of records cannot be selected, the cycle is repeated until the requisite number of records have been included within the output. Note that the application of a filter at an output can have an adverse effect on the ability to meet the number of required records quorum, meaning that additional pass(es) through data may be required.
Define attribute order: this button is available when Output sampling is set to one of Cap on attribute order or Nthing on attribute order. It allows you to define the order by which records will be selected when capping is applied across all of a split’s outputs. Selecting the button displays the Define Sampling Order Attributes dialog. The dialog contains the following:
Attributes list: the attributes used to determine the basis by which records will be chosen when capping is applied across the split's outputs are listed herein. At least one attribute must be provided for the audience to be valid.
You can add an entry to the list by dragging an attribute from the toolbox onto the list, or by selecting the Add new Sampling Order Attribute button.
For each list entry, the following are shown:Attribute: provision of an attribute is mandatory. You can browse for an attribute, or you can configure the property using drag and drop. You cannot select an exists in table or parameter attribute. Once an attribute has been provided, you can view its details in the File Information Dialog. You can also clear the selected attribute.
[Order]: this dropdown allows you to define the basis upon which records with values for the attribute are to be selected for capping. Two values are provided for the property: Ascending (the default) and Descending.
Actions meu: exposing the following options:
Move Up
Move Down
Remove
Not protected by “Are You Sure?”
Add new Sampling Order Attribute: this button adds a new, unconfigured row to the bottom of the list.
Close: selecting this button confirms your changes and removes the dialog from display.
On audience execution, split capping is applied to records in accordance with the stipulations made at the dialog.
For example, if an output is capped at 10%, Output sampling is set to Cap on attribute order, and Sampling order attributes are defined as Yearly Income (descending), followed by Commute Distance (descending), records with the highest income values will be selected first. Within that set, records with the lowest commute distance will be selected for inclusion within the capped cell.
Overall volume cap: an optional integer field that allows you to define an overall maximum number of records that can be output by the split block. For example, if you have a split block that produces three equal outputs capped at 10,000 records each, and you define an Overall volume cap of 15,000 records, the first output will contain 10,000 records, the second 5,000 records and the final output will be empty (but will still be created).
Outputs tab
A split's outputs define how its input data is to be segmented when it is run. Outputs listed in the Outputs tab:
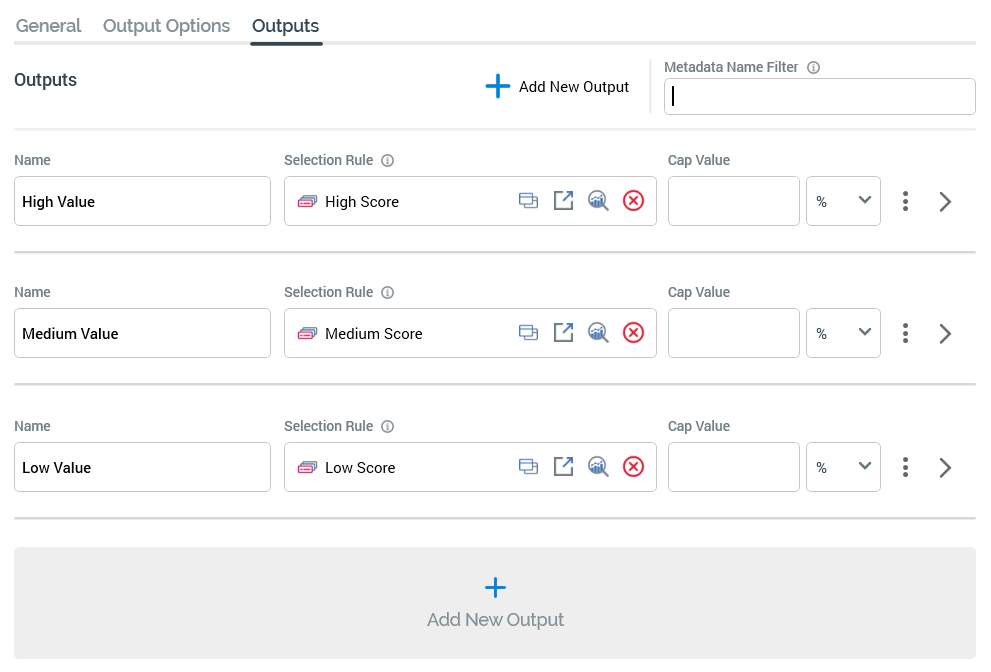
The list is initially empty, and a message is displayed that says “No Outputs have been configured”.
You can add a new output using the button shown at the bottom of the list.
If a record qualifies for inclusion in more than one output, it will appear in the output that appears first in the split. A split must contain at least one output.
You can filter the list of metadata attributes displayed at outputs using the Metadata name filter field, at which the following information tooltip is shown:

You can configure the following split output properties:
Name: an output's name may be a maximum of 100 characters and is mandatory. The name must be unique within the audience. By default, a new output is named ‘New Output’. If an output with this name already exists, the new output is called ‘New Output 2’ (note that this numerical value can be incremented if required).
Selection Rule: this optional property allows you to associate a split output with a selection rule. The rule is run when the split is executed. Only records that are targeted by the rule are included in the output.
You can associate a rule with an output by browsing the RPI file system, or by dragging a rule from the toolbox and dropping it onto the output. The link between the split and selection rule is dynamic—that is, the block is always linked to the most up-to-date version of the selection rule.
Having configured a split with a selection rule, an information icon is displayed to the right of the rule’s name.
Hovering over the icon displays an informational tooltip. If the audience is configured with a transactional audience definition, and the resolution of the selection rule is the same as the definition’s transactional resolution level, the message says “Filters both ‘Customer’ and their corresponding ‘Sales’ records that match this selection rule”.
In this example, the audience definition’s resolution level is ‘Customer’ and transactional resolution ‘Sales’.
In all other cases the message says “Filters ‘Customer’ records that match this selection rule”.
In this example, the audience definition’s resolution level is ‘Customer’.
Also having configured a split with a rule, you can invoke Open Latest version to display the rule in question in the Rule Designer. If the Designer is already open, the rule is displayed there. If the Designer is not open, the rule is displayed in a new instance of the Designer. You can also clear the property.
Note that you cannot use an anonymous auxiliary database-resolving selection rule in a Split block.
Cap Value: defines the value at which the output will be capped. For example, if Cap by volume or percentage is set to Volume, and Capping value to 10,000, a maximum of 10,000 records will be included in the output generated when the split is run. If Cap by... is set to Percentage and Capping value to 10, a maximum of 10% of the block’s total input records will be included in the output. If Cap by... is set to Volume, Capping value must be a positive integer. If set to Percentage, it must be a numerical value greater than 0 and less than or equal to 100. The maximum total percentage value across all split outputs must not exceed 100%. Similarly, if percentage caps totaling 100% exist within the split, and you add an additional value cap, the audience becomes invalid. Where the final output in a split exists without an explicit cap value, the output generated from the output will contain the remainder of records not picked up by preceding outputs.
Percentage/Volume: this field determines whether the output's cap—the maximum number of records to be included within the output—is defined as an explicit numerical volume value or as a percentage of the total of number of records output by the split. You can toggle the setting, which defaults to Percentage.
Metadata: you can override previously-assigned metadata attribute values at the split output level. A Metadata section appears at the bottom of an output and can be expanded or hidden as required.
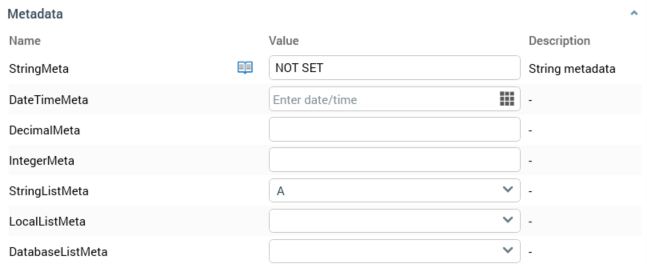
You can also revert a value to that which was assigned previously. You can use metadata parameters when specifying a string metadata attribute's value.
An inline menu button is also displayed at a split:
Actions: exposing the following options:
Move up
Move down
Remove
Not protected by “Are You Sure?”