

This tab allows you to define training sets, which are collections of attribute used when generating a clustered audience from a standard selection rule. For more information on clustered audiences, please see the Standard Selection Rule documentation.
The tab contains a list of training sets, and displays all training sets configured at the current audience definition.
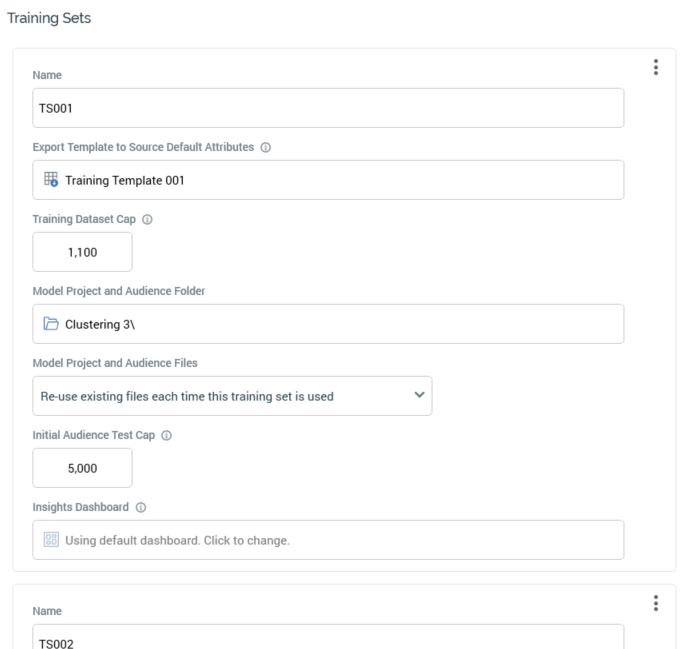
A training set exposes the following properties:
-
Name: this mandatory text property can be a maximum of 100 characters in length. All training sets within the current audience definition must have unique names.
-
Export template to source default attributes: you must select an export template for each configured training set. The export template is used as the basis for defining a set of attributes to be used during clustered audience generation. It is important to ensure that the selected template does not contain attributes not suitable for use at AML - e.g. unique identifiers such as a Customer Key. The selected template must be valid, be from the same database as the audience definition's Resolution level and must contain at least two attributes.
-
Training dataset cap: this mandatory integer property represents the maximum number of records to be passed to AML to train a clustering model when the training set is used. The property defaults to the value 10,000, which is also the maximum permitted.
-
Model project and audience folder: you must select an RPI file system folder, which will be used to save the model project and audience files created during clustered audience generation. You cannot select an external folder in this context.
-
Model project and audience files: this dropdown field exposes the following values:
-
Re-use existing files each time this training set is used: when this option is selected, rather than generating new model project and audience files for a particular selection rule, RPI will overwrite any existing files.
-
Create new files each time this training set is used: the default value. When this option is selected, RPI will generate new model project and audience files for a specific selection rule each time a clustered audience is generated.
-
-
Initial audience test cap: this integer property allows you to optionally apply a cap to the number of records used to run an audience test after model training is complete. The maximum permissible value is 999,999,999.
-
Insights dashboard: by default, the results of initial audience test execution will be displayed using the audience definition's Default Insights dashboard. You can select another dashboard here to overwrite the default, if required.
An Add new Training Set button is displayed at the bottom of the list. Selecting it adds a new training set. The new training set’s default name is “New Training Set” (an integer can be appended and, if required, incremented to ensure name uniqueness), and it is selected automatically. An inline Options menu gives access to a Remove option.