

Overview
COBOL is a legacy mainframe environment. For decades, corporations and governments have stored vast amounts of important information in COBOL data files, which are often undocumented and poorly understood. Getting this information out of the mainframe and into the hands of analysts is a big challenge. Data Management gives users tools to read these legacy files, work with the data in a productive software environment, and write the data to modern formats.
The COBOL Input tool reads flat-format records from COBOL data files, using the copybook associated with the data file to define the record schemas. The tool can process multiple record-storage formats, many code pages, and can handle big-endian or little-endian numeric data. It can process files containing multiple record types, and can optionally output these as a hierarchy of complex schema records on a single output connection.
COBOL Input tool configuration parameters
The COBOL Input tool has two sets of configuration parameters in addition to the standard execution options.
Configuration
|
Parameter |
Description |
|---|---|
|
Input file |
The file containing the records, or a wildcard pattern matching multiple files. |
|
Copybook |
Text layout file defining the schema of the COBOL input file. |
|
Record storage |
One of:
|
|
Code page |
Name of the encoding of the source data. This is optional and defaults to Latin-1 (ISO-8859-1). See About code pages. |
|
Byte order |
Endianness of binary values for integers and floats. Either Little endian or Big endian. |
Options
|
Parameter |
Description |
|---|---|
|
Limit records |
If selected, limits the number of records read. |
|
Read only the first |
If Limit records is selected, specifies the number of records to be read. |
|
Produce file name field |
If selected, the file name will be output as a record field. |
|
Output full path |
If Produce file name field is selected, optionally outputs the entire path to the record file name field. |
|
Output URI path |
If Output full path is selected, express path as a Uniform Resource Identifier (URI). |
|
Field name |
If Produce file name field is selected, name of the column to be used for the file name. This is optional and defaults to FILENAME. |
|
Field size |
If Produce file name field is selected, size of the field to be used for the file name. This is optional and defaults to 255. |
|
Override record length |
Select this to directly specify Record length. If this is not selected, Record length reflects the Copybook specification. |
|
Record length (bytes) |
Size of each record in bytes (including any newline characters). |
|
Data offset (bytes) |
The starting position of the record data in bytes, if other than zero. |
|
Output Unicode text fields |
Select this if you specify a Code page that cannot be mapped completely onto Latin-1 (ISO-8859-1), and you want to retain non-Latin-1 characters. For example, the code page CP1140 contains the Euro symbol (€), which does not exist in Latin-1. If your input code page is CP1140 and you do not enable Output Unicode text fields, all € characters will be replaced by ? characters. |
|
Generate _LINE field |
Select this to create a field containing a sequence number (_LINE) at the beginning of each record. When combined with the Use record selection logic option, you can order the records on multiple output connectors. |
|
Use record selection logic |
Select this and configure record selection rules to define record selection logic for choosing among multiple top-level record types or REDEFINES. |
Configure the COBOL Input tool
To configure the COBOL Input tool:
-
Select the COBOL Input tool.
-
Go to the Configuration tab.
-
Specify the Input file.
-
Specify the Copybook file. If the copybook cannot be parsed, a message will appear listing the line and column where the error occurred. See common copybook problems.
-
Once the copybook has been parsed, examine the copybook tree view. If the copybook contains multiple top-level record definitions, you will not be able to preview data at this point. If the copybook contains multiple top-level record types, or contains a top-level record type that is redefined multiple ways, you must specify rules that tell the COBOL Input tool which record to select based on data found in leading columns. Data Management cannot automatically deduce these rules from the copybook; you must specify them based on documentation about the file's format. See COBOL record selection and Configuring COBOL record selection.
-
Examine the sample records in the preview grid. If the preview does not look correct, Analyze the copybook file:
-
If you know the code page of your input file, select it from the Code page list, and then select Analyze

-
If you do not know the code page, select Analyze

-
Analyze typically will not work on files containing multiple record types until the record selection logic has been defined.
-
If Analyze fails to produce a valid configuration, review the copybook and data format documentation, and set the correct Record storage, Code page, and Byte order values:
-
Record storage may be Fixed length, Variable length, Newline delimited, Mainframe V, or Mainframe VB.
-
Code page is typically either CP037 (North American EBCDIC) or 8859-1 (Latin-1 and ASCII), but may be another encoding, especially for EBCDIC outside of North America.
-
Byte order is either big-endian or little-endian.
-
-
If the copybook contains REDEFINES clauses, specify how these should be interpreted. A set of REDEFINES at the top level may indicate the need for record selection logic, instead of simply choosing one record type alternative. If the copybook defines multiple record types at the top level and the record type is selected according to the content of certain fields, you must configure record selection logic on the Options tab instead. See the repository project
/Samples/COBOL/AmsReceiptMultifor an example.-
Use the up and down arrow buttons (


<ALL>to output all possible redefine alternatives (making the record wider). -
Select the

-
-
Optionally, select the Options tab and configure advanced options:
-
If you don't want to process the entire file, select Limit records and type the desired number of records to process.
-
To include the name of the input file as a new field, select Produce file name field and specify a Field name and Field size. Select Output full path to include the complete file specification. This can be useful when reading a wildcarded set of files. Select Output URI path to express the complete file specification as a Uniform Resource Identifier.
-
If the input record length is different than the length specified by the copybook, select Override record length and specify the correct Record length (bytes). This option is typically only needed with Fixed length or Variable length record storage. It is an alternative to editing the copybook and adding FILLER fields if the copybook specification is shorter than the actual record length.
-
If the input file has a data starting position other than zero, specify the correct Data offset (bytes). This option is typically only needed for unusual data files or files that have had a header added after a data dump.
-
If you specified a Code page containing characters that do not all map to the Latin-1 code page (typically seen outside of the Americas and Western Europe), select Output Unicode text fields.
-
To create a field containing a sequence number (
_LINE) at the beginning of each record, selectGenerate _Linefield. This is especially useful when you have multiple record types on separate connectors, and want to track their absolute order. -
To define record selection logic for choosing among multiple top-level record types or REDEFINES, select Use record selection logic and configure record selection rules.
-
If you have multiple top-level record types with record selection logic defined, you may select Use complex output to create a single output connector containing all record types in a variant record stream. See COBOL complex-schema output and Configuring COBOL complex-schema output.
-
-
Optionally, go to the Execution tab and Enable trigger input, configure reporting options, or set Web service options.
Once the COBOL Input tool has been correctly configured, you should see data in the preview window.
It often takes several iterations of copybook editing and data review before you have a copybook that matches the data correctly.
If you have multiple top-level record types with record-selection rules, the field names displayed in the preview window will be labeled f1, f2, f2... because there are no common field names across all record types.
Common copybook problems
If you see a "COBOL input file cannot be parsed" error, the problem may be the copybook. Open the copybook file with a text editor and examine the line and column specified by the COBOL Input tool's error message.
Some common problems with copybooks:
-
Lines are too long: the COBOL standard reserves columns 73 and up. Data Management attempts to parse longer lines, but this is not always possible.
-
Missing line-number and comment columns: columns 1-7 are reserved for line numbers and comments. Data Management attempts to parse copybooks missing these columns, but this is not always possible.
-
Invalid redefines: a REDEFINE statement must refer to a group or record type that has already been defined.
-
Data mismatch: because COBOL data is often exported by a process that is disconnected from the copybook, the copybook may not match the data. To confirm that the problem is a mismatch between data and copybook, examine the COBOL data with a hex editor. If the data deviates from the copybook, edit the copybook to conform to the data.
COBOL record selection
If your data file contains multiple record types, the corresponding copybook will describe either multiple record types at the top level, or one record type that is redefined multiple times. Data Management handles both of these the same way.
If your data file contains multiple record types and Record storage is Variable length, Data Management will be unable to read the file until you define record selection rules. If your data file contains multiple record types and Record storage is not Variable length, Data Management may be able to read the file, but some of the records may contain errors or a FILLER field.
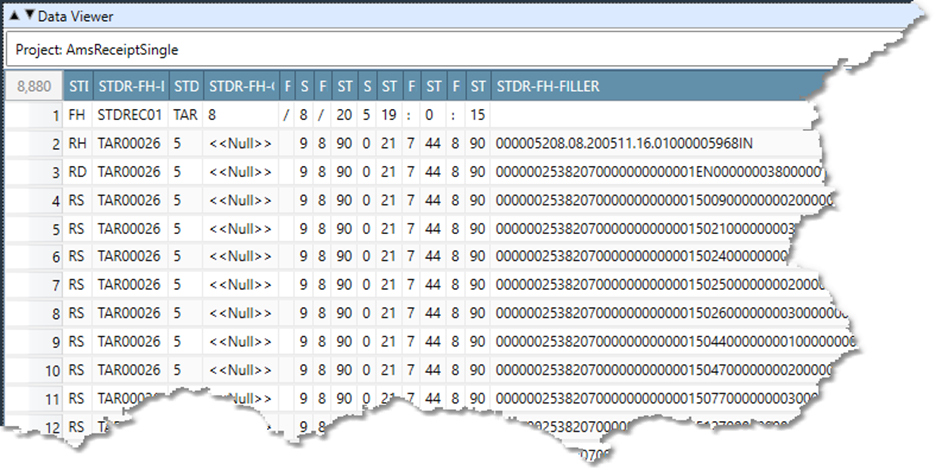
You can view the erroneous data shown above by opening and running the repository project /Samples/COBOL/AmsReceiptSingle.
Data files containing multiple record types often have a record type code in one or two leading columns. The values in these columns may correspond to the names of the top-level record definitions in the copybook. However, this is entirely by convention; there is no standard for how multiple-record types correspond to field values in the records. You must either infer the relationship by guessing, or consult the creator of the file and copybook (or its documentation). Once you understand the rules governing the relationship between data in the file and record types, you can configure the COBOL Input tool to conform to these rules. To see an example, open the repository project /Samples/COBOL/AmsReceiptMulti.
Configure COBOL record selection
To configure the Blob Input tool:
-
Configure the COBOL Input tool with the desired Input file, Copybook, and Format options.
-
Select the Options tab, and choose Use record selection logic.
-
If there is a Default record type, enter it. This is the record type that will be used if no other decision can be made based on the data.
-
Use the Multiple record types grid to specify each record type. On each line:
-
Select the target Record type.
-
In Field1, select the field containing the data value that selects for this record type.
-
In Value1, enter the data value that selects for this record type.
-
Optionally, enter a second field/value pair in Field2 and Value2 to further refine the selection rule.
-
These rules are processed in order. In the event of any ambiguity in the rules, the earlier rule wins.
COBOL complex-schema output
You may find it easier to handle COBOL data with multiple record types using the complex-schema method. In this method, all record types are sent down a single output connector in a variable format.
Using the complex schema method, you can:
-
Preserve the order of input records more easily.
-
Convert to XML or delimited format using a single Complex XML Output or Complex Text Output tool.
-
Express a nesting hierarchy.
To see an example of this method, open the repository project /Samples/COBOL/AmsReceiptComplex. This example also demonstrates conversion of the nested records to XML and delimited formats.
Use of the complex schema method may require purchase of an additional license feature key.
Configure COBOL complex-schema output
To configure the COBOL complex-schema output tool:
-
Go to the Options tab and choose Use complex-schema output.
-
Optionally, use the Complex record nesting grid to specify nesting relationship. On each row, enter a parent and child record type.
Typical nested file formats will have a header record, with all other records children of the header record.