

Overview
The RDBMS Execute tool reads data from an RDBMS table or query, executes a parameterized statement on each input record, and sends the results to the output connector. This allows you to move beyond the standard query/insert/update/delete logic of Data Management's RDBMS Input and Output tools.
The tool executes the SQL statement once for each input record. Any ? placeholders in the SQL statement will be filled in with mapped parameters from the fields of the input record.
Example: query records from an input table using logic unavailable in the RDBMS Input tool.
SELECT * FROM CUSTOMERS WHERE NAME=? AND AGE_YEARS < ?
In this example, you would map two parameters (NAME and AGE) from the input record. You would also connect the output to receive the query results.
Example: delete records from a table using logic unavailable in the RDBMS Output tool.
DELETE FROM TRANSACTIONS WHERE DATE=? OR CUSTOMER_ID=?
The RDBMS Execute tool can also be used to execute stored procedures via the CALL statement. Stored procedures are database-specific, and they can do almost anything, but the syntax for calling them is simple:
CALL <stored_procedure_name>(?,?,...)
where stored_procedure_name is the name of the stored procedure to call, and each ? is a placeholder for a parameter to be mapped into the RDBMS Execute tool.
The RDBMS Execute tool and Oracle
The RDBMS Execute tool can also be used for inserting into Oracle databases using a sequence variable to produce auto-increment behavior, as discussed here under the Syntax for Oracle heading. You would first create the sequence variable outside of Data Management:
CREATE SEQUENCE my_seq
MINVALUE 1
START WITH 1
INCREMENT BY 1
CACHE 10
Suppose you have a table called Person with three column names: Id, FirstName, and LastName. You could use the following statement to get the "next" value from the sequence variable and use it during the insert, along with the parameters mapped onto FirstName and LastName:
INSERT INTO MyTable (Id,FirstName,LastName) VALUES (my_seq.nextval,?,?)
The RDBMS Execute tool and BigQuery
In cases where a result set is expected by a downstream tool, note that BigQuery providers will not emit an error if the query defined in the RDBMS Execute tool returns no results.
RDBMS Execute tool configuration parameters
The RDBMS Execute tool has three sets of configuration parameters in addition to the standard execution options: Source, Options, and SQL.
Source
The Source tab defines the connection to the RDBMS data source.
|
Option |
Description |
|---|---|
|
Use data connection |
If selected, gets the connection parameters from the specified data connection in the Repository. |
|
Database |
Select a database provider to configure appropriate connection options and set up a fill-in-the-blank grid for defining necessary parameters. |
Options
The Options tab controls detailed behaviors of the database operations. See Configuring options.
SQL
The SQL tab defines the record input parameters.
|
Parameter |
Description |
|---|---|
|
SQL |
Specify a parameterized SQL statement to be executed on each record. |
|
Parameter mapping
|
Specify field names referenced by |
|
Include fields
|
Specify field names to include on output. |
Configure the RDBMS Execute tool
-
Select the RDBMS Execute tool.
-
Go to the Source tab.
-
Configure a database connection, or select Use data Connection and then select a data source from the list.
-
Optionally, select the Options tab and configure database options.
-
Select the SQL tab, and then type an SQL statement in the SQL box. This statement will be executed once for each input record. Use the
?character as a placeholder for any value that you want to map from the input records.
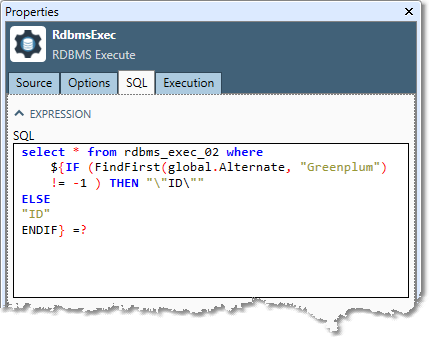
-
In the Parameter mapping grid, select an input field for each
?placeholder in the SQL statement. The parameters are mapped in the same order as in the SQL statement.
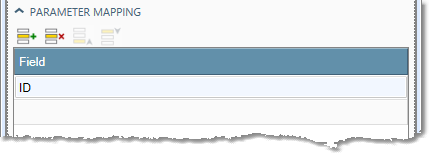
-
In the Include fields grid, you may optionally select any fields from the input record that you want to be included in the output record.
-
Optionally, go to the Execution tab, and then set Web service options.