

Overview
The topics in this section address the most common problems reported by Data Management users. If you experience an issue that is not addressed in this documentation, please contact technical support.
Troubleshoot projects
-
The Data Viewer tool is your best friend. If your results don't look right, attach Data Viewer tools to different points in your project, give them different names, and observe your records as they move through the system. Verify that each tool is doing what you think it should.
-
Verify your assumptions about input data. For example, suppose that all customer records should have a valid name. You can verify this by connecting a Filter tool, setting its expression to NAME!="", and checking that the "N" output is blank by connecting either a Data Viewer tool or a file-output tool.
-
Use the Sort tool in conjunction with a Data Viewer tool to examine your data in a particular order. This is often handy for finding "problem records" containing unexpected values. For example, suppose you perform some revenue calculations and the results have wildly high figures. A good double-check is to sort the input transaction records by amount, and look for very high or very low values.
-
Use the Summarize tool in conjunction with a Data Viewer tool to verify your assumptions and validate data. Summarize is good for obtaining quick counts and totals. For example, you might summarize a sales history by territory. This gives you immediate feedback about the quality of your sales data, with answers to such questions as: "Are there any sales assigned to non-existent territories?" and "Do all my totals look right?"
-
Use the Join tool in conjunction with Data Viewer tools to verify that parent/child relationships are met by your data. If two tables are related parent-child fashion by a specific key, then the "left outer" and "right outer" results of a Join on that key should be empty.
Troubleshoot memory and disk use
In addition to displaying messages from projects you have run, Data Management's log viewer can help you identify tools that are using too much memory or disk space.
-
Open and run a project.
-
View the Management Dashboard and select Logs

-
Double-click the Projects entry at the bottom of the Logs list.
-
Locate the project run on the Logs list, and select it. Notice the Messages button in the lower panel.
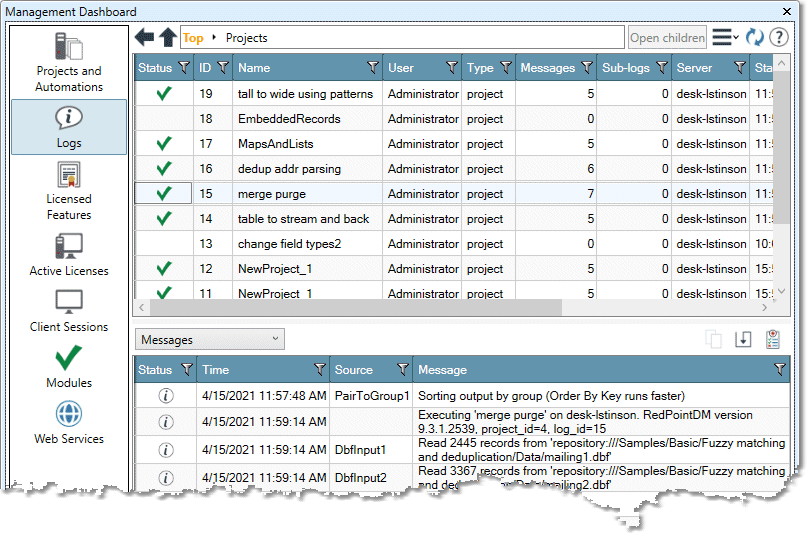
-
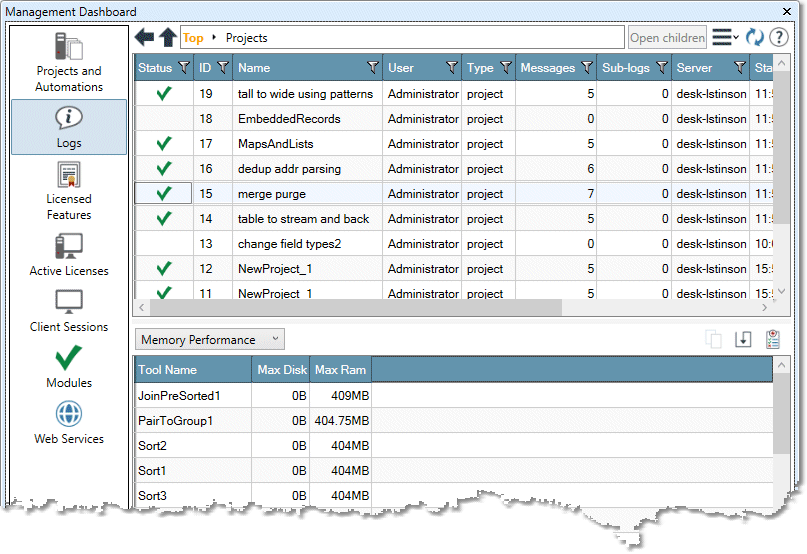
Select the Messages drop down and choose Memory Performance to view the tools in the project that use temporary disk space or RAM. The tools using the most space are listed first.
Track down errors
To identify where error values are being generated:
-
Create a Filter tool containing the expression:
IsError(FIELD)(using your field name instead ofFIELD). -
Connect the "Y" output of the Filter to a Data Viewer tool.
-
Configure the Data Viewer tool to have a title of "Errors" so it's easy to identify.
-
Connect the Filter/Data Viewer pair to the place in your project where you first observed the error. If you are getting errors on output, then connect the Filter/Data Viewer pair just upstream of the output tool.
-
Run the project and view the results.
-
Disconnect the Filter/Data Viewer pair and reconnect it "upstream" in the project. Keep doing this until you no longer get error records in the viewer (or until you have it attached to an input tool). When you're finished, you've pinpointed the location where error values are being produced.
If error values are produced by an input tool, there is a problem in the interpretation of the input data.
For example, suppose you are reading a CSV file. You have specified an input field as type Date, but when Data Management scans the values in the file, the field values do not match the specified format. The input tool might be misconfigured, requiring you to reconfigure the field to match the format of the data. Or there might be bad data in the file. In this case, you'll need to figure out what to do with the bad data. You can filter on IsError(FIELD) to separate bad records for review or processing. You can also use a conditional expression such as IF IsError(FIELD) THEN Null ELSE Error ENDIF to change Error values to Nulls (which may be better for your process).
If you find that error values are produced by some intermediate tool in the project, take a hard look at what the tool is doing to the offending field. Check for the usual culprits: numeric overflow, divide-by-zero, failed conversions from text to other types, and propagation of Error values used in expressions. Remember that if you put an Error value into a calculation, you'll get another Error value out.
Project runs slowly
Some reasons that a project may run more slowly than expected:
-
You are performing a Cartesian Join on duplicate data. See Job stops responding with Join tool highlighted.
-
You have specified a network drive as a temporary directory. Use a local disk instead.
-
You are writing output files to a network drive. Use a local disk instead.
-
Your disk drives are fragmented or almost full. Data Management uses sequential disk access. Running on a highly-fragmented or almost-full disk drive will slow processing. This is true for both the disks containing data and the disk being used for temporary files.
-
Other disk-intensive processes are running on the same computer. Data Management runs much more slowly when competing for disk resources.
-
Your computer is low on physical memory.
Error: "Cannot open file for reading"
A file input tool (such as DBF Input) may display the error "Cannot open file for reading". Check that the file exists and is in the correct directory, and then press F5 or select Refresh on the Edit menu. If you are using relative file paths, ensure that the working directory contains the file of interest.
Project fails with "Cannot open file..." error
The error Cannot open file C:\temp\Data Management123.tmp for writing usually indicates inadequate disk space.
If the specified file is a temporary file (for example, C:\temp\ Data Management 123.tmp), you are running out of temporary disk space (see About temporary disk space). Remember that Data Management uses a considerable amount of disk space for operations like sorting and joining, as well as for splitting a data path.
If the file is an output file, you do not have enough space to store the results. However, if you are writing temporary files to the same disk drive as the output file, you may be running out of space because the temporary files compete with your output file for disk space. Try setting the temporary directory to a different drive than the one the output file is being written to.
Project hangs with Join tool highlighted
A project that "hangs" with a Join tool highlighted is usually the result of joining two tables on a field that has many duplicate values. Remember that if you set the Join type to Cartesian, it will create a huge number of output records when both inputs have duplicate values in the field used for the Join operation. This is a common problem when you have many NULL or blank values. Depending on the nature of your processing, there are two possible solutions:
-
Are you joining on a field that has blank or NULL values? If so, consider placing a Filter tool upstream of the Join tool, and remove any records containing blank or NULL fields from consideration. This would be appropriate, for example, if you are trying to match two databases by PHONE and the databases contain many blank PHONE values.
-
Do you really want a full Cartesian join? Suppose that you want to find all customers of Department A having ZIP codes that overlap with the ZIP Codes of Department B's customers. A Join on ZIP code will almost certainly take forever, because both lists have many duplicate ZIP values. In a case like this, you really want to join the Department A list against the unique list of ZIP codes for Department B. You can do this by placing a Unique tool on Department B upstream of the Join tool. See the sample project unique3.dlp for an example of this technique.
Project runs out of disk space and fails
Data Management requires a lot of disk space for temporary files. In general, it may require two to three times as much temporary space as the size of your input data.
Data Management requires that you configure the temp disk space for each Execution Server, and allows you to specify more than one disk for temporary space, which Data Management will use in parallel.
If you do not have adequate disk space available on your system, changing the directory won't help. Instead, try one or more of the following approaches:
-
Add another disk drive to your system
-
Free space on your disk by removing unneeded files
If you are joining large record sets, and one of them is unique on the join keys but the other is not, connect the non-unique input to L and the unique input to R. This will run faster and reduce the temp space required by the Join tool.
Output fields contain "Error" values
The value Error in an output field is Data Management's way of formatting error values that result from improper calculations or conversions. Some common causes of this are:
-
Overflowing a numeric field: for example, if you attempt to assign the value 100000 to a fixed-point field that is five digits wide, an error will result. You must also be careful when totaling field values. A field that is large enough to hold each individual entry of a transaction log may not be large enough to contain the sum of all transactions.
-
Failed conversion of values from input files: for example, if you read a flat ASCII file, and configure an input field as a Date type, any field values that cannot be read as Dates (such as "Data Management") become error values.
-
Failed conversions using the Calculate or Retype tools: both of these tools can convert the type of a field. For example, you can convert a Text field to a Date field, assuming that the Text can be scanned as a Date. If some data is non-conforming, error values will result.
-
Divide-by-zero errors: if you attempt a calculation using the divide operation with a denominator of zero, the result will be an error value.
Warning: Error values converted to Null
If the data you are writing to a file or database contains "Error" values, those values are converted to Nulls before being written to the file or database. Data Management does this because most database formats do not support an explicit Error value.
If you are getting these warnings, either your input data or your project has problems. See Tracking down errors for more information about identifying the source of Error values.
Message "errno6"
If advanced security mode is enabled, you should either specify a Default domain, or specify a fully qualified OS User for each Data Management user (unless your Active Directory configuration supports logons without a domain). Users with logons that do not include a domain may be unable to open or create projects and automations, and may see an error message like errno6.
Network monitor
The Network Monitor, accessed from the File menu, is a debugging utility intended for use by Data Management support services.
Enable core dumps on Linux
Enabling core dumps on Linux can be useful in various scenarios, especially for debugging and troubleshooting purposes.
To enable core dumps for RPDM on Linux, follow these steps (as root):
-
Edit the file:
/etc/redpointdm9.conffor RPDM v9 -
Add the following line to the end of the file and save it:
ulimit -c unlimited. -
Restart the RPDM services.
If you are not seeing coredump files being generated in the RedpointDM directory, this could be due to the OS level not allowing this action to happen.
Please refer to a solution provided by RHEL on how to enable the core dumps: How to enable core file dumps when an application crashes or segmentation faults.