

Overview
The XML Input2 tool reads nested XML-formatted data, and outputs records to the "downstream" tools. The tool can transform nested XML into a relational data model and produce multiple outputs. The number of outputs and their labels is specified during configuration.
To automate output definition, you can import a predefined repository schema specifying field names, field descriptions, and (optionally) field sizes. Note that linkage fields (ID fields that associate parent and child records) must be of type Integer (4).
XML Input2 tool configuration parameters
The XML Input2 tool has two sets of configuration parameters in addition to the standard execution options.
Configuration
|
Parameter |
Description |
|---|---|
|
Input from |
The source of the data:
The Split list data source is for Redpoint Global Inc. internal use only. |
|
Input file |
If Input from is File, the file containing the records, or a wildcard pattern matching multiple files. |
|
Input field |
If Input from is Field, the field from which the data will be read. If you are connecting to an upstream Web Service Input tool, this is |
|
Include input fields |
If Input from is Field, optionally passes through the "extra" input fields to the "root" record. This can be useful in certain kinds of processing where it is desirable to carry through identifying information that is not represented in the XML2 documents. |
|
Use repository schema |
If selected, configure the field layout using the specified Schema instead of configuring fields directly. |
|
Schema |
If Use repository schema is selected, a schema must be specified. |
|
Validate XML |
If selected, performs XML-level validation against any DTD referenced by the input file when the project is run. |
|
Record |
Record specification defining the input of the tool. This is difficult to configure manually. See Configuring the XML Input2 tool. |
|
Path |
Sequence of XML tags separated by |
|
Filter |
If specified, a Filter for one or more Outputs. This is a Boolean expression to detect variant records within an Output. The filter must evaluate to |
Options
|
Parameter |
Description |
|---|---|
|
Limit records |
If selected, limits the number of records read. |
|
Produce file name field |
If selected, the file name will be output as a record field. |
|
Output full path |
If Produce file name field is selected, optionally outputs the entire path to the record file name field. |
|
Output URI path |
If Output full path is selected, express path as a Uniform Resource Identifier (URI). |
|
Field name |
If Produce file name field is selected, name of the column to be used for the file name. This is optional and defaults to |
|
Field size |
If Produce file name field is selected, size of the field to be used for the file name. This is optional and defaults to |
|
Validate XML |
If selected, validates the XML document against any DTD or Schema referenced in the document. |
|
On XML error |
If Validate XML is selected, action to take upon detecting an error in the XML input. Options are Fail project (default) and Isolate error to file. |
|
Use namespaces |
If selected, causes Analyzer to retain variant prefix/namespace mappings. |
|
Entity map |
If defined, a map from external entity URLs referenced in the XML document to local files containing those entities, used to resolve external DTDs and schemas that are unavailable at their original location. A map entry contains a From (the URL found in the document) and a To (a file path or new URL). |
|
Namespace map |
If Use namespaces is selected, mapping between Prefix and URI values. |
|
Error handling |
Configures how errors in the input data will be handled:
|
|
Parsing errors |
Specify how to handle input containing invalid XML that cannot be processed. The Issue warning option is not available for this type of error. |
|
Conversion errors |
Specify how to handle input data that cannot be correctly converted to its specified data type (such as converting "Jane Smith" to a Date). |
|
Truncation errors |
Specify how to handle input with truncated field values (such as storing "John Smithson" in a Unicode(1) field). |
|
Missing fields |
Specify how to handle input with fields that are missing or contain empty values. |
|
Extra fields |
Specify how to handle input with extra elements that are not defined in the tool's configuration. |
|
Send errors to Message Viewer |
If selected, all error types configured to either Issue warning or Reject record will send warnings to the Message Viewer. The Report warnings option must be selected on the Execution tab. |
|
Send errors to Error Report connector |
If selected, creates an E "Error Report" output connector. All error types configured to either Issue warning or Reject record will send detailed error messages to that connector. Attach a downstream Data Viewer or other output tool to review these messages. |
Configure the XML Input2 tool
The procedure for configuring an XML Input2 tool depends on the data source.
|
If the data source is... |
Do this |
|---|---|
|
A file or files |
|
|
A field or datastream |
...to read files
To configure the XML Input2 tool to read files:
-
Select the XML Input2 tool.
-
Go to the Configuration tab on the Properties pane.
-
Select Input from and choose File, and then specify the input file or files. You can use wildcards to configure a single XML Input2 tool to read a sequence of files with the same layout and format.
-
Define the input format.
|
If you have... |
Do this |
|---|---|
|
An XML schema for this file already defined in the repository. |
Select Use repository schema, and select the schema from the drop-down list. |
|
No schema defined for this file. |
Select Analyze |
-
Select each cell in the Record column, and examine the field grid to verify that the schema is correct and the data is accurately described. See About XML paths for details.
Linkage fields (ID fields that associate parent and child records) must be of type Integer (4).
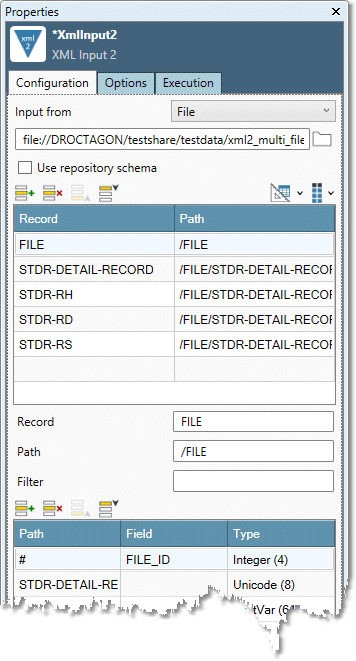
Record streams are represented by labeled arrows on the bottom of the XML Input2 tool icon. The labels take the first letter of the Record.
-
Optionally, specify a Filter for one or more Outputs. This is a Boolean expression to detect variant records within an Output. If specified, the filter must evaluate to
Truefor the record to be output. -
Optionally, select the Options tab and configure advanced options:
-
If you don't want to process the entire file, select Limit records and type the desired number of records to process.
-
To include the name of the input file as a new field, select Produce file name field and specify a Field name and Field size. Select Output full path to include the complete file specification. This can be useful when reading a wildcarded set of files. Select Output URI path to express the complete file specification as a Uniform Resource Identifier.
-
Select Validate XML to validate the XML document against any DTD or Schema referenced in the document.
-
The Data Management Analyze function normalizes prefix mappings to create a single 1:1 namespace mapping. Select Use namespaces and re-analyze to use variant prefix/namespace mappings.
-
Configure the Entity map grid to override the location of referenced entities. External entities referenced by an XML document (DTDs and Schemas) are sometimes not found at their referenced URL or cannot be accessed due to firewall restrictions. To specify an alternate location for a referenced entity, enter the URL of the entity as seen in the XML document in the From column. In the To column enter either an absolute file path (like
f:/schemas/airbase.xsd) or an alternate URL (likehttp://acm.eionet.europa.eu/schemas/airbase/airbase20100623.xsd). -
Configure error handling.
-
-
Optionally, go to the Execution tab and Enable trigger input, configure reporting options, or set Web service options.
...to read fields
To configure the XML Input2 tool to read fields:
-
Select the XML Input2 tool.
-
Go to the Configuration tab on the Properties pane.
-
Select Input from and choose Field. If you are connecting to an upstream Web Service Input tool, this is
requestBody. -
Select Commit

-
Select the Input field from which the data will be read, and then define the input format.
|
If you have... |
Do this |
|---|---|
|
An XML schema for this file already defined in the repository. |
Select Use repository schema, and select the schema from the drop-down list. |
|
No schema defined for this file. |
Select the Analyze tab and enter a formatted sample of the expected JSON input. Select Analyze The Analyze tab is only available when Input from is set to Field. To detect namespace use in the data sample, select Use namespaces on the Options tab. By default, Analyze ignores namespaces. |
Field data must be binary. If necessary, use an upstream Calculate tool configured with the BinaryRecastFromText function to convert the input data to type binary.
-
Select each cell in the Record column, and examine the Fields grid below to verify that the schema is correct and the data is accurately described. See About XML paths for details.
Linkage fields (ID fields that associate parent and child records) must be of type Integer (4).
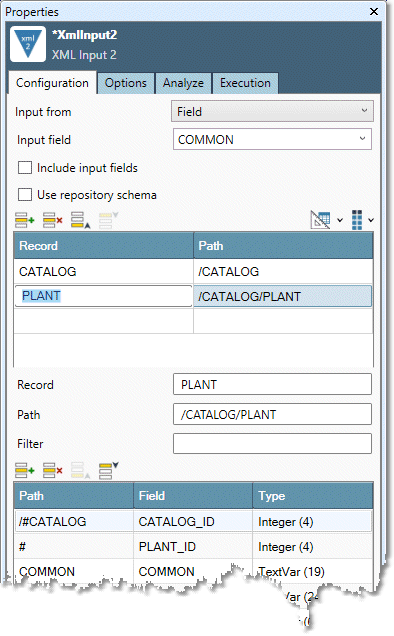
Record streams are represented by labeled arrows on the bottom of the XML Input2 tool icon. The labels take the first letter of the Record.
-
Optionally, specify a Filter for one or more Outputs. This is a Boolean expression to detect variant records within an Output. If specified, the filter must evaluate to True for the record to be output.
-
Optionally, select the Options tab and configure advanced options:
-
If you don't want to process the entire file, select Limit records and type the desired number of records to process.
-
To include the name of the input file as a new field, select Produce file name field and specify a Field name and Field size. Select Output full path to include the complete file specification. This can be useful when reading a wildcarded set of files. Select Output URI path to express the complete file specification as a Uniform Resource Identifier.
-
Select Validate XML to validate the XML document against any DTD or Schema referenced in the document.
-
The Data Management Analyze function normalizes prefix mappings to create a single 1:1 namespace mapping. Select Use namespaces and re-analyze to use variant prefix/namespace mappings.
-
Configure the Entity map grid to override the location of referenced entities. External entities referenced by an XML document (DTDs and Schemas) are sometimes not found at their referenced URL or cannot be accessed due to firewall restrictions. To specify an alternate location for a referenced entity, enter the URL of the entity as seen in the XML document in the From column. In the To column enter either an absolute file path (like
f:/schemas/airbase.xsd) or an alternate URL (likehttp://acm.eionet.europa.eu/schemas/airbase/airbase20100623.xsd). -
Configure error handling.
-
-
Optionally, go to the Execution tab and Enable trigger input, configure reporting options, or set Web service options.
XML paths
Data Management supports the following XML Path elements.
|
Element |
Meaning |
|---|---|
|
|
Separator between segment of the path (for example, |
|
|
The Nth occurrence of the give path segment. For example, |
|
|
Indicates the value of the attribute |
|
|
Indicates a synthetic numbering operation. The
|
|
|
Indicates the element at the current path. Normally used to pull values from the path of an output specification. |
|
|
Indicates the parent segment in the path. For example, if the output's |
Many paths can produce ambiguous results if there are multiple occurrences of the given path. In such cases, the last instance before the closing tag of the record is used.
XML paths that specify items at a level above the Path of an output item (i.e., elements in the ancestor records) cannot "reach forward". For example, suppose you have this XML document:
<A>
<B>
<C>c1</C>
<D>d1</D>
</B>
<B>
<C>c2</C>
<D>d2</D>
</B>
<X>x</X>
</A>
You can define an output whose Path is /A/B and define fields within this path.
|
FIELD |
PATH |
|---|---|
|
|
|
|
|
|
|
|
|
The value for X in this output will be null for both records, because no X tag is encountered before the closing tag of the records. All parent values output in child records must be occur in the XML document before the child records. A solution is to join the parent and child outputs together after the XML Input2 tool.