

Introduction
This document provides a comprehensive overview of a secure and scalable approach to onboarding external data sources. These sources can include a variety of formats and types, such as relational tables, NoSQL collections, cloud files, or streaming events. The primary objective of this approach is to ensure that all data is unified, activated, and governed in an efficient manner within the Redpoint platform. Implementing this strategy helps you effectively manage your data integration processes, thereby enhancing your overall data management capabilities. Defining these ingestion patterns will streamline the data onboarding process and allow you to more efficiently and consistently add additional data sources to the system.
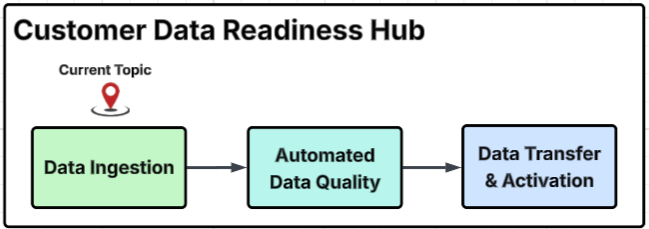
Customer Data Readiness Hub diagram
This diagram outlines the primary process steps within the Customer Data Readiness Hub, provides a detailed breakdown of specific activities within each major group, and identifies the particular step addressed on this page with the "Current Topic" marker.
Guiding principles
|
Principle |
Application in Data Sourcing |
|---|---|
|
Open connectivity |
Use native Redpoint connectors when possible; otherwise, use JDBC/ODBC, SFTP, or REST. Refer to the Connectors topic for more information. |
|
Canonical data model |
Map all incoming data to Redpoint’s standardized subject areas using a “feed layout.” Refer to the Data Ingestion: Basics topic for more information. |
|
No-code first |
Prefer visual pipeline tools and drag-and-drop transformations; use Python/SQL only for complex cases. Refer to the Data Ingestion topic for more information. |
|
Incremental by default |
Use Change Data Capture (CDC) or timestamp filters to minimize load and simplify downstream processing. |
|
Data quality built-in |
Enforce validation, profiling, identity resolution, and archival in every pipeline. Refer to the Data Ingestion: Basics topic for more information. |
|
Security everywhere |
Encrypt data in transit and at rest, vault credentials, and apply RBAC tags for access control. |
High-level architecture
-
Source connectors: Redpoint supports various data sources, including relational databases like Oracle, SQL Server, Postgres, MySQL, and DB2. It also accommodates cloud data warehouses such as Snowflake, BigQuery, Redshift, and Databricks. The system handles NoSQL and streaming data sources, including MongoDB, Kafka, and Kinesis. Additionally, it integrates with file and object storage solutions like S3, Azure Blob, Google Cloud Storage (GCS), and SFTP, as well as SaaS applications and REST endpoints, providing a comprehensive data ingestion framework.
-
Landing & staging: In the initial stages of data processing, raw data is securely copied into a cloud object store. Automated schema drift detection recognizes and manages changes in the data schema. Metadata cataloging maintains an organized repository of data attributes and structures, facilitating easier access and management.
-
Conformation layer: The Feed Layout Mapper standardizes source columns to align with the canonical model, including entities like Party Profile and Transaction. This standardization ensures consistency across the data. Validators check for required fields, verify data types, maintain referential integrity, and implement PII (Personally Identifiable Information) masking to protect sensitive data.
-
Processing & identity resolution: The system performs batch and streaming transformations, including deduplication, match and merge operations, and data enrichment, enhancing data quality and usability. It also allows for third-party data augmentation, integrating external data sources to further enrich the dataset.
-
Curated store: Once conformed, the data is stored in the platform’s schema, ensuring organization and accessibility. These conformed tables are propagated to analytical marts and real-time hubs. This structured approach supports robust analytics and reporting capabilities.
-
Monitoring & observability: The platform includes monitoring and observability features that enable users to track pipeline metrics, assess data quality KPIs, and understand data lineage. Alerts notify users of SLA (Service Level Agreement) breaches or validation failures, ensuring data integrity and operational standards are maintained throughout the data processing lifecycle.
Onboarding workflow
|
Phase |
Key activities |
Owner |
|---|---|---|
|
Source discovery |
Inventory systems, cadence, data volume, and security posture |
Data eng. + SME |
|
Connector enablement |
Configure/adapt required adapters |
Platform ops |
|
Feed-layout mapping |
Map fields, set keys, choose incremental logic, register in UI |
Data engineering |
|
Sample load & validation |
Test with sample records, verify against layout rules |
QA |
|
Initial backfill |
Bulk/parallel historical load, throttle as needed |
Data engineering |
|
Automation & scheduling |
Set triggers, define retry/quarantine strategy |
Platform ops |
|
Go-live & monitoring |
Cutover, validate counts, activate alerts, document lineage |
Data ops |
Connector implementation patterns
-
Direct DB pull (JDBC/ODBC): This method is designed specifically for transactional relational database management systems (RDBMS) that are under 1TB in size and support Change Data Capture (CDC). It allows for efficient and direct extraction of data from the database, facilitating real-time or near-real-time data access.
-
Bulk unload + file ingest: This approach is particularly useful for handling large fact tables or data warehouses. An example of this would be using Snowflake's
COPY INTOcommand, which allows for the bulk unloading of data from a source and subsequent ingestion into a target system. This method is optimal for managing vast amounts of data efficiently. -
Streaming (Kafka/Kinesis): This technique is utilized for processing near-real-time events. By leveraging platforms such as Kafka or Kinesis, organizations can capture and analyze streaming data continuously, enabling timely insights and responses to events as they occur.
-
API polling/webhooks: This method is applicable for Software as a Service (SaaS) systems that utilize REST or GraphQL APIs. By employing API polling or webhooks, data can be retrieved or pushed from these systems, ensuring that the latest information is always available for processing and analysis.
-
Third-party ETL: This strategy is essential for integrating data from proprietary or legacy sources. It involves landing data in object storage, which can then be accessed for further processing. This approach allows organizations to manage and utilize data from various sources effectively, ensuring that valuable information is not lost or overlooked.
Data quality & transformation controls
-
Standardization: The process of standardization involves unifying various elements such as date and time zones, currencies, and character sets to ensure consistency across different systems and platforms. This is crucial for maintaining a coherent data environment, especially in global operations where discrepancies can lead to confusion and errors.
-
Cleansing & enrichment: This step includes activities like postal verification to ensure addresses are accurate, maintaining phone and email hygiene to prevent outdated or incorrect contact information, geocoding to convert addresses into geographic coordinates, and performing enrichment lookups to enhance data with additional relevant information that can provide deeper insights.
-
Validation rules: This involves checking for completeness to make sure all necessary information is present, uniqueness to avoid duplicates, referential integrity to maintain accurate relationships between data elements, and adherence to specific business rules that govern how data should be structured and utilized.
-
Audit & lineage: The audit and lineage processes are vital for capturing metadata, which includes elements such as feed-ID, run-ID, row counts, and error codes. This metadata allows you to track data flow, understand its origins, and identify any issues that may arise during processing, maintaining a clear audit trail to ensure compliance and enhance data governance practices.
Security & compliance
-
Manage credentials: Use OAuth 2.0 and IAM roles for managing credentials to ensure a secure and standardized method for authorization and access control.
-
Secure communication: Employ TLS 1.2 or higher to guarantee secure communication for all data transfers. Additionally, use SFTP with key-based authentication during file transfers to further enhance security.
-
Protect PII: Protect Personally Identifiable Information (PII) by encrypting PII fields at the column level using AES-256 encryption to add a robust layer of security to sensitive data.
-
Maintain privacy compliance: Implement fine-grained Role-Based Access Control (RBAC) alongside data-subject tagging to maintain privacy compliance with regulations such as GDPR and CCPA and help ensure that access to personal data is strictly controlled and monitored.
-
Automate purge & archive: Automate the purge and archive policies tailored to each data feed to streamline data management processes and ensure that data retention policies are consistently applied.
Operational best practices
-
Implement incremental loads, and as the system matures and requirements evolve, adjust the frequency up to real-time loads as necessary. This gradual approach allows for a more manageable transition and ensures that the system can handle increased data flow effectively. Although you could start with real-time data ingestion, typically when building these systems there is a need to load historical data, which is often provided in large data sets and loaded incrementally and in batch to validate the load process and data itself.
-
Develop and establish reusable connector templates that can be utilized across various projects to streamline the setup process and minimize configuration drift, ensuring consistency and reliability in data connections.
-
Parallelize the processes involved in file parsing and database extracts to enhance performance and efficiency. Additionally, appropriately size the landing zone's IOPS (Input/Output Operations per Second) to accommodate the increased load and ensure optimal data handling.
-
Maintain a strict Service Level Agreement (SLA) for the transition from raw data to conformed data, ensuring that this process does not exceed twice the cadence of the data feeds. This guideline helps manage data freshness and reliability.
-
Implement version control for feed layouts and mappings using pipeline code to track changes over time and to also provide a clear history of modifications, making it easier to manage and revert if necessary.
-
Conduct a monthly review of lineage dashboards to monitor data flow and integrity. During these reviews, identify and consider retiring any dormant feeds that are no longer in use, thereby optimizing the data pipeline and maintaining its effectiveness.
Next Steps
-
Finalize the source inventory: Thoroughly review all potential data sources and prioritize them based on their business value and the complexity involved in integrating them. The goal is to identify which sources will provide the most significant impact on the business while also considering the effort required for their integration.
-
Select pilot feeds for testing purposes: Include critical data sources such as CRM customers and POS transactions in your pilot feeds and conduct comprehensive end-to-end testing to identify issues early in the integration process and ensure that the data flows smoothly from these sources.
-
Build and test connector templates: Create the necessary connections between the data sources and the target systems. Additionally, implement automated quality gates during this phase to ensure that the data being transferred meets the required quality standards and is free from errors.
-
Publish run-books and Service Level Agreements (SLAs) to the operations team: Provide guidelines and expectations for the ongoing management and operation of the data feeds, ensuring that everyone involved is aware of their responsibilities and the standards to meet.
-
Iterate: Continue the cycle of improvement after the initial implementation, focusing on extending the integration to more data feeds, enabling Change Data Capture (CDC) capabilities, and integrating real-time data streams. This iterative approach ensures that the system evolves and adapts to changing business needs and technological advancements.
For detailed onboarding steps and examples, refer to Data onboarding example sequence of events.
Refer to Redpoint CDP onboarding for details about how Redpoint enables data ingestion in the Redpoint CDP.