

Introduction
Identity resolution is the process of matching, merging, and relating signals to the correct entity (person, household, account) using deterministic and probabilistic rules, resulting in a governed, consent-aware identity. Redpoint’s identity resolution approach is people-first, explainable, and governance-led to create a durable, consent-aware identity for each customer, unifying interactions across all sources and timeframes. This is achieved through transparent, tunable match logic and robust data stewardship enabled by the Redpoint platform.
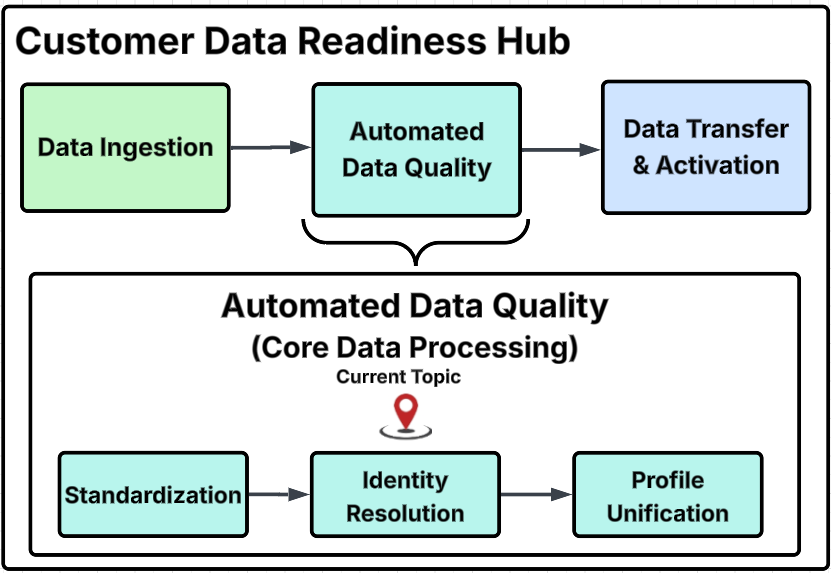
Customer Data Readiness Hub diagram
This diagram outlines the primary process steps within the Customer Data Readiness Hub, provides a detailed breakdown of specific activities within each major group, and identifies the particular step addressed on this page with the "Current Topic" marker.
Capability stack
-
Ingest & quality: Standardization, parsing, validation, and normalization of names, phones, emails, addresses, and IDs.
-
Identity graph: Links people, households, devices, accounts, and events.
-
Matching & scoring: Deterministic keys plus configurable fuzzy rules (weights, thresholds, tie-breakers, negative rules).
-
Golden Record & survivorship: Attribute-level precedence, data lineage, and steward controls.
-
Consent & policy layer: Preference and purpose binding, audit trails, and region-specific constraints.
-
Real-time recognition: Edge APIs/SDKs for live customer recognition.
-
Activation & analytics: Segment and orchestrate in Redpoint Interaction; expose Golden Records and diagnostics to downstream tools.
Core principles
-
People-first, needs-driven: At the heart of our approach is a commitment to a people-first philosophy grounded in clear customer needs and business outcomes. Identity is resolved only to support explicit use cases—whether that requires a broader, more inclusive match for marketing personalization or a tighter, higher-confidence match for fraud prevention and risk mitigation. Importantly, all resolution is governed by consent and policy, ensuring customer rights and preferences are respected throughout.
-
Explainable over opaque: We prioritize transparency in our operations by utilizing rule-driven, clear scoring mechanisms. This approach enables data stewards to easily read, test, and approve the processes involved. While we do incorporate machine learning into our systems, it is only applied when it demonstrably enhances accuracy and remains subject to auditing, thereby maintaining a high standard of accountability.
-
Deterministic-first, probabilistic-enhanced: Our identity resolution framework is built on a strong foundation of deterministic keys, such as account IDs or logins. These keys are then supplemented with configurable fuzzy logic to account for variations in names, addresses, devices, and user behaviors. This combination ensures a robust and flexible approach to identity management.
-
Accurate and reliable identity data: We maintain that each individual should have a governed and versioned golden profile. This profile is meticulously crafted with survivorship rules and granular control over the contents of the profiles. This ensures that the identity data we hold is accurate and reliable.
-
Real-time + batch: Our systems are designed to recognize customers in mere milliseconds at the edge of our network. Simultaneously, we are committed to continuously enhancing identities through nightly or streaming consolidation processes. This dual approach allows us to maintain up-to-date and accurate customer profiles.
-
Consent & compliance by design: The design of our systems inherently incorporates consent, customer preferences, and regional compliance policies. These elements dictate what data can be matched, stored, and activated, ensuring that we operate within legal and ethical boundaries while honoring customer choices.
-
Open & portable: We believe in the power of open systems. Our use of open connectors, APIs, and export functionalities ensures that identity data can seamlessly enrich your entire technology stack, including business intelligence, activation strategies, and customer care initiatives. This openness fosters greater integration and utility of identity data across various platforms.
-
Measure what matters: In our pursuit of excellence, we focus on tracking metrics that truly matter. This includes precision and recall rates, match rates, reductions in duplicate records, the completeness of Golden Records, and the overall business lift achieved—not merely technical throughput. By concentrating on these key performance indicators, we can ensure that our identity management practices deliver real value to the organization.
What does “good” identity resolution look like?
When we discuss the concept of identity resolution, it is essential to understand the characteristics that define what a "good" identity resolution process entails.
-
Accuracy: This means achieving a high level of precision when merging identities, which translates to minimal occurrences of false positives. Furthermore, it is crucial to have well-governed workflows in place that facilitate un-merging when necessary, ensuring that the integrity of the data is maintained.
-
Coverage: A robust identity resolution system should demonstrate high match rates across all priority channels. This includes not only digital platforms, such as web and app interfaces, but also traditional channels like email communications, call centers, point of sale (POS) systems, and loyalty programs. The ability to effectively match identities across these diverse channels is vital for comprehensive customer understanding.
-
Freshness: It is imperative that updates to identity information occur promptly, particularly in response to new events such as logins, purchases, and changes in consent. Keeping identity data current ensures that organizations can engage with their customers in a timely and relevant manner.
-
Explainability: This means having a clear hierarchy of rules that govern how identities are resolved, as well as a transparent lineage of attributes. Stakeholders should be able to understand the rationale behind identity decisions, which fosters trust in the system.
-
Safety: This involves being consent-aware, enforcing policies that protect user data, and ensuring compliance with regional regulations. Organizations must prioritize the privacy and security of their customers' information to maintain their trust.
-
Actionability: This means that it should facilitate easy segmentation and activation of data within platforms like Redpoint Interaction and also allow for seamless integration with external destinations. The ability to act on resolved identities effectively is what ultimately drives business value.
By focusing on these key characteristics, organizations can ensure that their identity resolution processes are not only effective but also aligned with best practices in data management and customer engagement.
Deployment patterns
There are several deployment pattern strategies that organizations can adopt to ensure efficient and effective updates to their systems and applications.
-
Batch-first: This approach involves a periodic (e.g., nightly) consolidation process that allows for a rapid initial rollout of updates. By gathering and processing data in batches regularly, organizations can ensure that they are ready to implement significant changes promptly. This method is particularly beneficial for systems that do not require constant updates throughout the day, as it allows for a more manageable and organized deployment schedule.
-
Hybrid (batch + streaming): This deployment pattern combines the benefits of both batch processing and streaming updates, enabling near-real-time updates for key events. By leveraging both methods, organizations can ensure that they remain responsive to critical changes while still maintaining the efficiency of batch processing for less time-sensitive updates. This hybrid approach allows teams to balance the need for timely information with the operational efficiencies gained from batch processing.
-
Real-time edge: In this deployment pattern, the focus is on achieving millisecond recognition for digital channels. This approach is essential for applications that require immediate feedback and interaction, such as those in e-commerce or real-time analytics. By utilizing real-time data processing, organizations can enhance user experience and ensure that they are meeting the demands of their customers effectively and efficiently.
Each of these deployment patterns offers unique advantages and can be selected based on the specific needs and goals of the organization.
Governance & operating model
-
Change control:
-
Versioned rules: Establishes a systematic approach to managing changes in processes and rules, allowing for tracking and accountability.
-
Environment promotion: Involves moving changes through various environments (development, testing, production) to ensure stability and performance.
-
Full audit trails: Maintains comprehensive logs of all changes made, providing transparency and traceability for compliance and review purposes.
-
-
Runbooks:
-
SOPs for merge/unmerge: Standard Operating Procedures that outline steps for merging or unmerging data sets, ensuring consistency and accuracy in data management.
-
Subject rights: Guidelines for handling requests related to individual rights under data protection laws, such as access, correction, and deletion of personal data.
-
Incident response: Procedures for responding to data breaches or other incidents, detailing steps for containment, investigation, and communication.
-
-
Quarterly calibration:
-
Review KPIs: Regular assessment of Key Performance Indicators to evaluate the effectiveness of processes and strategies.
-
Adjust thresholds as needed: Modifying performance thresholds based on the review to ensure they remain relevant and aligned with business objectives.
-
Sample configuration artifacts
Match rule hierarchy:
-
Tier 0 (auto-merge): Same
Customer_IDorHashed_Login_ID. -
Tier 1: (
Email_Normalized+Last_Name_Soundex) score ≥ 98. -
Tier 2: (
Phone_E164+PostalCode5) score ≥ 95. -
Tier 3 (fuzzy):
Name_Similarity≥ 93 ANDAddress_Similarity≥ 92, with no negative rules triggered. -
Negative rules: Different DOB, country, or conflicting government ID block merges.
Survivorship:
-
Email: Most-trusted source, else most recent valid.
-
Address: Most recent verified, else highest completeness.
-
Phone: E.164 valid from trusted source, else most recent.
Householding:
-
Same normalized street + unit and last name similarity ≥ 95, or shared account number, unless opted out.
Anti-patterns to avoid
-
Over-merging with aggressive fuzzy thresholds and no negative rules: This can lead to incorrect data associations and a lack of clarity in identity resolution. Establish clear boundaries and rules to prevent unintended merges that could compromise data integrity.
-
Frozen rules that don’t evolve with new channels/IDs: Rigid rules can hinder adaptability and responsiveness to changing environments. Regularly review and update rules to accommodate new data sources and channels, ensuring that the system remains effective and relevant.
-
Black-box ML without evidence trails: Utilizing machine learning models without transparency can create trust issues and make it difficult to understand decision-making processes. Implement traceability and documentation for ML models for accountability and validation of outcomes.
-
Activating profiles without clear consent: Engaging users without their explicit consent can lead to privacy violations and damage trust. Establish clear consent mechanisms and communicate the implications of profile activation to users.
-
Siloed identity with no APIs/exports: Isolated identity systems can create inefficiencies and hinder data sharing across platforms. Develop APIs and export functionalities for seamless integration and collaboration, allowing for a more holistic view of user identities.
Roadmap & next steps
-
Confirm KPIs and data sources: To measure success and track progress effectively, ensure that the key performance indicators (KPIs) are clearly defined and that the relevant data sources are identified and accessible for analysis.
-
Set up data profiling and match sandboxes: Establish environments for data profiling to analyze the quality and structure of the data. Additionally, create match sandboxes to test data matching algorithms and ensure they function correctly before full deployment.
-
Validate and tune rule hierarchy: Review and refine the hierarchy of rules that govern data processing and decision-making. This involves validating existing rules and making adjustments to optimize performance and accuracy.
-
Enable real-time recognition for priority channels: Implement systems that allow for real-time data recognition and processing, particularly for channels that are deemed high priority. This will enhance responsiveness and improve user experience.
-
Establish governance cadence and dashboards: Develop a regular governance schedule to review data practices and outcomes. Additionally, create dashboards that provide visual insights into data performance and compliance, enabling stakeholders to make informed decisions.
FAQs
-
How does Redpoint handle anonymous-to-known identities?
Redpoint employs a process that involves stitching together session and device identifiers and linking them to a specific individual when a deterministic signal is detected. Examples of such signals include actions like user login or the provision of a verified email address. Importantly, this method is underpinned by clear evidence and thorough consent checks, ensuring that user privacy and data protection are prioritized throughout the process. -
How are mistakes corrected?
Stewards have the capability to unmerge identities, which allows for the rectification of any inaccuracies while maintaining a complete lineage of changes. Furthermore, the rules and thresholds that govern these processes are versioned and auditable, providing transparency and accountability in the management of user data. -
Can we combine rule-based and ML?
Absolutely—in this hybrid approach, ML can be utilized to propose potential candidates or generate scores based on data analysis, while the established rules serve to enforce guardrails that ensure compliance and maintain explainability. This combination allows for a more dynamic and responsive system that leverages the strengths of both methodologies.