

Introduction
Data standardization is the process of unifying data formats, schemas, and values (e.g., names, addresses, emails, phone numbers) to ensure consistency and reliability across all systems and channels. This is a foundational step in the process of achieving reliable and unified customer profiles, enabling seamless data activation across various channels, and ensuring that organizations can effectively utilize their data.
This topic outlines Redpoint’s philosophy, guiding principles, and practical approach to data standardization, providing insights into how you can implement standardization effectively within your organization.
Redpoint’s philosophy on data standardization
Redpoint’s approach is to standardize the data once and reuse it everywhere; that is, create a single, governed data environment—covering schemas, identity, consent, events, reference data, and data contracts—and enforce it through configuration, automation, and promotion gates in our platform. This ensures:
-
Reliable, “golden record” customer data
-
Faster onboarding of new sources and channels
-
Consistent downstream activation and measurement
-
Higher match rates and accuracy
-
Shorter build cycles and provable compliance
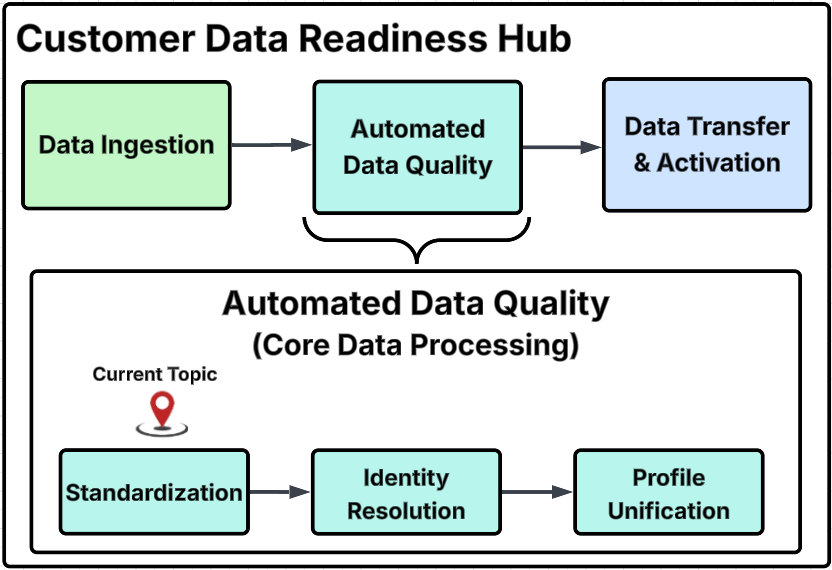
Customer Data Readiness Hub diagram
This diagram outlines the primary process steps within the Customer Data Readiness Hub, provides a detailed breakdown of specific activities within each major group, and identifies the particular step addressed on this page with the "Current Topic" marker.
Core principles
-
Canonical-first: Establish a canonical model, a single source of truth, that serves as the foundational framework for representing key entities such as people, households, events, consent, and reference codes, ensuring consistency and clarity across applications and systems.
-
Config over code: Enforce governance through configurations rather than relying on custom scripts. This includes the use of schemas, rules, and lookup sets, which allow for easier management and updates while minimizing the risk associated with hard-coded solutions.
-
Identity-centric: Treat the principles of identity and consent as non-negotiable standards within the framework. Design all other components and processes to align with and support these core tenets, ensuring that they remain at the forefront of any operational strategy.
-
Validation at the edge: Implement rigorous schema checks and data quality rules to prevent data drift at the point of ingestion. Address potential issues proactively rather than adopting a reactive approach of “fixing it later,” which can lead to greater complications down the line.
-
Versioned & composable: Use small, versioned building blocks, such as “Address v2” to facilitate safe and manageable changes. This approach allows for incremental updates and enhancements without disrupting existing systems, promoting a more agile and responsive development environment.
-
Evidence-driven: Evolve standards based on measurable metrics related to adoption, quality, and performance. Relying on evidence and data-driven insights allows you to make informed decisions that enhance operational effectiveness and ensure that standards remain relevant and impactful.
Scope of standardization
Redpoint plays a crucial role in defining and enforcing a comprehensive set of standards to maintain consistency and quality across various data management processes:
-
Canonical customer & party schema: A structured framework for representing entities such as individuals, accounts, and households, including the definition of keys, attributes, and flags for Personally Identifiable Information (PII) to ensure that data is organized and compliant with privacy regulations. Refer to Redpoint's approach to hygiene, matching, and identity resolution for detailed information about name, address, email, phone standardization parsing and validation processes.
-
Identity resolution standards: Guidelines for identity resolution, including creating match keys, thresholds for determining matches, survivorship rules for managing conflicting data, and a deduplication policy to eliminate redundant entries.
-
Consent & preference model: Requirements for obtaining and managing consent, emphasizing purpose-based consent mechanisms. This model addresses the source of consent, proof of consent, expiry dates, and jurisdictional considerations to ensure compliance with legal standards.
-
Event model: Standardized naming conventions for events, requiring uniform event names and defining the necessary attributes that must be included. It also establishes timestamp semantics and identity binding protocols to ensure accurate event tracking.
-
Reference data: The creation of code sets that categorize essential reference data such as country, channel, language, currency, and lifecycle stage to ensure consistency in how data is referenced and utilized across various applications.
-
Data quality policies: Data quality enforcement that specifies requirements for fields, including whether they are required or nullable. It also includes type and domain checks, format rules, and remediation processes to address any data quality issues that may arise.
-
Data contracts for activation: Detailed specifications for data activation, including the order of fields, data types, encoding formats, null-handling procedures, and error semantics.
-
Lineage & metadata: Defining the owner of the data, its sensitivity level, service level agreements (SLA), retention policies, version control, and tagging for easier data management and retrieval.
KPIs to prove value
|
KPI |
What it measures |
Why it matters |
|---|---|---|
|
Schema conformance rate |
The ratio of valid records to rejected records. |
Provides insight into the quality and consistency of the data being processed. A high conformance rate indicates that the data adheres to predefined schemas, which is crucial for maintaining data integrity and usability. |
|
Duplicate rate & stitch quality |
The effectiveness of deduplication efforts by comparing pre- and post-deduplication rates. It also assesses the match confidence distribution. |
Helps to understand how accurately records are stitched together, ensuring that unique profiles are maintained without redundancy. |
|
Golden Record coverage |
The percentage of profiles that possess a Golden Record ID, a unique identifier. |
Ensures data accuracy and assesses attribute completeness, highlighting how well the profiles are enriched with necessary data points, which is essential for effective data utilization. |
|
Consent coverage & enforcement |
The number of deliveries that are blocked by policy compared to the total number of attempted deliveries. |
It is critical for compliance with data protection regulations and ensuring that user consent is respected in all data transactions. |
|
Event integrity |
The rate of duplicate or late events, as well as the success of ID binding processes. |
High event integrity is vital for maintaining the reliability of event-driven systems and for accurate event tracking. |
|
Activation reliability |
The contract validation pass rate. |
Indicates how often contracts meet the necessary criteria for activation. It also tracks the rollback count, which reflects the number of times an activation process had to be reversed, providing insight into the reliability of the activation process. |
|
Time-to-onboard |
The number of days required to add a new source or channel while using existing standards. |
A shorter onboarding time indicates a more efficient process, which can enhance the overall agility of the data management system. |
Example starter standards
Canonical customer (excerpt)
|
Field |
Type |
Required |
Notes |
|---|---|---|---|
|
|
GUID |
✓ |
Golden Record ID issued by CDP |
|
|
string |
|
Validated; survivorship-ranked |
|
|
string |
|
UTF-8; title-case normalization |
|
|
date |
|
ISO-8601; jurisdictional use flags |
|
|
structured |
|
Postal standards; geocoded where allowed |
|
|
array |
|
Provenance, |
Consent (purpose-based)
|
Field |
Type |
Required |
Notes |
|---|---|---|---|
|
|
GUID |
✓ |
Links to Golden Record ID |
|
|
enum |
✓ |
E.g., marketing.email, personalization |
|
|
enum |
|
Email, SMS, push, mail |
|
|
enum |
✓ |
Granted, denied, withdrawn |
|
|
enum |
|
E.g., GDPR, CCPA |
|
|
string |
|
Capture method, evidence URI |
|
|
datetime |
|
ISO-8601 |
Risk controls & guardrails
-
PII boundary checks at ingest and pre-activation; block exports violating policy. This ensures that any personally identifiable information (PII) is properly managed and safeguarded from the moment it is ingested into the system, preventing any unauthorized exports that could compromise user privacy and violate established policies.
-
Consent enforcement at decision time; no send without valid purpose. This process guarantees that data is only shared or utilized when there is a legitimate reason to do so, ensuring that user consent is respected and upheld throughout the decision-making process.
-
Data drift alerts for conformance, match-rate drops, or unusual event volumes. Implementing alerts for data drift allows for proactive monitoring of data integrity and consistency, helping to identify any discrepancies or unexpected changes in data patterns that could indicate underlying issues.
-
Immutable audit logs for schema/rule/contract changes; rollback plans and change windows. Maintaining immutable audit logs is crucial for tracking changes to schemas, rules, and contracts, providing a reliable history of modifications. This also includes having rollback plans and defined change windows to ensure that any changes can be reverted if necessary, minimizing disruption and maintaining system integrity.
How Redpoint services accelerate the journey
-
Standards catalog: This includes a comprehensive collection of ready-to-use canonical models, an event taxonomy, data quality (DQ) rules, and match policies that are essential for maintaining consistency and accuracy across various data processes. These elements work together to ensure that all data adheres to established standards, facilitating better data management and utilization.
-
Promotion pipeline pack: This pack consists of critical components such as schema definitions, personally identifiable information (PII) management, and consent gates, along with segmentation regression tests. These elements are designed to streamline the promotion of data through different stages of processing while ensuring compliance with privacy regulations and maintaining the integrity of the data.
-
Onboarding playbooks: These playbooks provide a set of repeatable steps that guide users through the process of adding various sources and channels in accordance with the established standards. They serve as a practical resource for teams to ensure that the onboarding process is efficient, consistent, and aligned with best practices, ultimately enhancing the overall workflow.