

Overview
The Unicode standard defines over a million "code points" or unique characters, and contains definitions for almost all languages in the world. Please refer to the following for a introduction to Unicode:
Data Management supports Unicode with a Unicode data type. Fields in Data Management that are of type Unicode can store all text that is representable by the Unicode standard, which is almost everything that can be processed as character data. Unicode fields are always variable-length. Internally, Data Management stores Unicode text in the UTF-16 format. This format was chosen because it is a good balance of compactness and speed. The old TextVar data type still exists alongside the new Unicode data type.
About code pages
Not all data files use Unicode. Files containing international text can use any of hundreds of different representations, many of which support only a subset of the characters that are in the Unicode standard. These representations are called encodings, and the specific mapping of bytes to characters is called a code page. Each encoding and code page is a mapping between sequences of bytes in the data and the characters that they represent. Refer to the following for more details: Wikipedia: Code page.
Data Management uses only two code pages internally: Latin-1 (also known as ISO/IEC 8859-1) and UTF-16 (a two-byte encoding within the Unicode standard). Within Data Management, all processing assumes that TextVar fields contain Latin-1 and all Unicode fields contain UTF-16.
Data encoded with other code pages must be converted to either Latin-1 or UTF-16 as it is read into Data Management, or converted from Latin-1/UTF-16 as it is written from Data Management. The following Data Management tools can convert data encoded with other code pages:
-
COBOL Input tool: converts from the specified code page.
-
CSV Input tool: converts from many code pages.
-
Flat File Input tool: converts from many code pages.
-
RDBMS Input tool: converts nvarchar columns to Unicode fields.
-
XML Input2 tool: converts from the encoding defined in the XML header.
-
CSV Output tool: converts to many code pages.
-
Flat File Output tool: converts to many code pages.
-
RDBMS Output tool: converts to nvarchar columns.
-
JSON Input, JSON Output, XML Output, and XML Output2 tools: do not convert specific code pages, but convert everything to/from UTF-8.
Review Code pages for a complete list of code pages supported by International Components for Unicode (ICU).
Reading Unicode data
The CSV Input tool directly supports Unicode as well as the conversion of Unicode and TextVar data from many Code pages. If you have a delimited text file with an unknown encoding, you can select Analyze and select Analyze all (detect codepage), and Data Management will "guess" the code page for you. It is correct about 75% of the time. If you know the code page, select the correct code page from the Code page list box and then select Analyze. If the code page is correctly specified, the sample data will display correctly after analysis. For help choosing code pages, refer to Wikipedia: Code page.
Code page names are non-standard. You might know a code page by its common name (such as "Big5") but not see that name on the Code page list. You can type the name that you know ("Big5") and it will often work, because that name will be one of the known code page aliases. Once you specify the correct code page and select Analyze, the analysis may produce both TextVar and Unicode columns. Data Management chooses TextVar if all characters found in the column are representable in the Latin-1 code page; otherwise it chooses Unicode.
You may choose to use the TextVar data type for input fields that contain international text data. Doing so will cause the data to first be converted to Unicode, and then Latin-1. Any non-representable characters are replaced with question mark character (?).
The RDBMS Input tool will read nvarchar database columns, and present them to Data Management projects as Unicode. However, if you select the Convert Unicode to Latin-1 option, Data Management converts nvarchar text stored in the database to type TextVar, and replaces non-representable characters with a question mark character (?).
Writing Unicode data
The CSV Output tool directly supports Unicode, and the conversion of Unicode and TextVar data to many code pages. If the upstream connection to the CSV Output tool contains Unicode columns, and you need to represent all characters in the output file, you should choose a code page other than the default Latin-1. The code page you choose will depend almost entirely on the intended use of the file and user requirements. For help choosing code pages, refer to Wikipedia: Code page.
Code page names are non-standard. You might know a code page by its common name (such as "Big5") but not see that name on the Code page list. You can type the name that you know ("Big5") and it will often work, because that name will be one of the known code page aliases.
The RDBMS Output tool will read Unicode or TextVar fields from the upstream connection, and convert them to either varchar or nvarchar database columns. The conversion is automatic, and based on the upstream field types and the database column types. However, if you select the Convert Unicode to Latin-1 option, it will affect the creation of new tables by forcing all columns to be varchar instead of nvarchar. When the table is loaded, any varchar columns that are loaded with Data Management Unicode fields will have non-convertible characters replaced with a question mark character (?).
The XML Output2 and JSON Output tools always convert both TextVar and Unicode fields from the upstream connection to the only supported output format, UTF-8.
Unicode in expressions
All text expressions in Data Management are Unicode, and all functions in Data Management that accept text will process Unicode. TextVar or TextFixed data types in an expression are automatically converted to Unicode. Storing the result of an expression into a TextVar field will convert from Unicode to Latin-1, replacing any non-representable characters with a question mark character (?).
Sorting Unicode text
When you sort Unicode text data, it sorts according to the code points of the text. It does not honor any "natural" collation order. This can produce unexpected results, as accented versions of characters often sort in radically different positions than the unaccented counterparts.
|
These words |
Sort in this order |
|---|---|
|
Beta |
Alpha |
|
beta |
Beta |
|
Zed |
Zed |
|
zed |
alpha |
|
Alpha |
beta |
|
alpha |
zed |
|
Álpha |
Álpha |
|
ālpha |
ālpha |
If you want text to be ordered without consideration of accents, use the RemoveAccents and (optionally) Lowercase functions before sorting.
Matching Unicode text
The Window Compare tool and the EditDistance function operate on Unicode text by ignoring accents and case. Thus, they treat A, a, Á, and ā as the same entity. However, remember that the Window Compare tool does not establish the sort order; that is usually accomplished using an upstream Sort tool. If you want the data to be ordered without consideration of accents or case, use the expression Lowercase(RemoveAccents(FIELD)).
Parsing Unicode text
The parsing tools and all of the regular expression functions are Unicode-enabled. In particular, the regular expression meta-characters (such as a, W, and d) correctly represent the Unicode character sets.
Tools with no Unicode support
All Data Management tools accept Unicode data. However, some do not process Unicode data completely. For example, the Standardize Address tool accepts Unicode fields, but does not process any characters above the Latin-1 range. The following tools do not have complete support for Unicode, converting Unicode to Latin-1 before processing:
Displaying Unicode text
The Data Management client can display the entire Unicode character set. However, the required fonts are slower and often less readable than the default font. This font will display most text in the Americas, Europe, and Middle East.
To specify a Unicode-compatible font in the Data Management client:
-
Select Data Rendering Settings on the File menu.
-
Select Use a Unicode compatible font, and then choose a font family from the list. Lucida San Unicode is included with Windows 10.
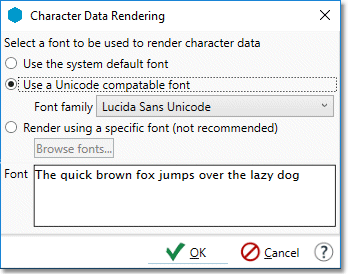
-
Quit and restart the client.
-
While the Data Rendering Settings contain an option to Render using a specific font, you should only use this to display international or unusual character sets. Specifying a overly large or small font, or a font that does not correctly display the basic Latin characters, may cause instability and usability issues. Do not not specify a custom font for purely aesthetic reasons.
-
If you cannot find a font that correctly displays all data, or if no fonts are available in the drop-down list, you may need to install a font (on your client computer). Lucida Sans Unicode is typically included with Windows 10. To determine whether this font is on your system or network, search for the file l_10646.ttf. See Microsoft's Windows 10 font list for more information.